This is a space for me to jot down notes as I prepare for system desgin interview rounds. This will also (hopefully) help keep me accountable in actually taking the necessary steps to effectively become proficient in system design.
The Plan
This video has a solid 4 step plan to get prepared for system design interviews:
- Understand what is expected
- Refresh/learn the fundamentals
- Learn the basic building blocks used in common system design interview problems
- Practice with commonly asked problems and extract patterns from each problem
I plan on using this 4 step process, but I think switching 1 and 2 would be best for me because I think understanding the fundamentals first will help me understand more clearly what is expected. So my process will be:
- Refresh/learn the fundamentals
- Understand what is expected
- Learn the basic building blocks used in common system design interview problems
- Practice with commonly asked problems and extract patterns from each problem
I will hopefully be working through these steps in the coming months. I am writing this as of July 20th, 2025. I am hoping to be proficient within the next 2-3 months.
The Fundamentals
Storage
How data is persisted in a system, whether it be structured or unstructured data is one of the most essential parts of a system. It is important to know that different databases and storage systems have different advantages that are useful for different data types and data access patterns.
Databases
Data can be stored in many formats
Records/Tables
The most popular data format is storing data as rows/records in a table.
- This is useful when the structure and the fields of data are well defined an not likely to change
- It is fast to perform “joins” on tables such that you can make queries across multiple tables for data that may be related.
- Data correctness can be maintained because of the rigid nature and forced types
Documents
Document DBs store data in a JSON like nested format
- It does not have a defined schema for the data, so it is flexible with data with different fields and structures
- Good for when your data model can be changing more frequently.
- Good for data locality, as data for a record can be embedded within a record, unlike tables where you may need to perform some complex join.
- Good for horizontal scaling because data is easily partitionable
Graphs
Sometimes it is better to model data as a network of relationships
- Data is stored as nodes with metadata and edges that connect the nodes together, also with metadata.
- Good for when the relationship between objects is important (e.g. Social networks).
Scaling Databases
There are two ways to scale your database. First is vertical scaling. This is quite simple, you just add more disk space to your database node.
Horizontal scaling is a little more complex. It can happen in two ways: Replication and Sharding. These two methods can be used together as well.
Replication
- Replication is when you distribute the same data across multiple database nodes. This is useful not when space is your bottleneck, but throughput is your bottleneck. Your system needs to be able to handle more requests per second.
- By distributing the data across multiple nodes, you can relieve the stress on one node by giving multiple nodes to perform reads or writes on.
- Single Leader Replication
- This is when you only use a single node for writes for a DB, but you replicate the writes from DB to all other nodes.
- This is good for when your read throughput is much higher than your write throughput.
- It will not help your write throughput, as you are still bottlenecked by one node
- Less likely to have conflicts in writes. Can probably still have ACID guarantees because of only 1 writing node.
- Good scaling option when you don’t make a lot of writes, but you make a large amount of reads.
- Multileader/Leaderless Replication
- This allows for multiple nodes to accept write requests to the DB, and data has to be replicated from all DB nodes to each other.
- ACID guarantees here is only possible with a huge decrease in performance, which is not worth. You are more likely to have write conflicts.
- You can make eventually consistent guarantees, which basically means the data between all databases will eventually converge to the same state.
- Good to use when you need to handle a large amount of reads and writes, and it is not super important for the data to be accurate and consisten right away.
Partitioning
- Good mainly for when data storage is your bottleneck (though it also does help with throughput bottleneck)
- You have to split your data in to multiple shards because your original node simply did not have enough space.
- It is common to assign records to partitions based on a specific attribute/key of the data (e.g. all IDs 0-1MM go to shard 0, 1MM-2MM go to shard 1, etc.)
- You want to make sure that one DB node does not become a hotspot because of natural data distrbution. It is good to use some hashing function to make the distribution of the keys more random/uniform and use consistent hashing to have better distribution of data.
Combining both
You can combine partitioning and replication to scale your database in all directions. Say you have nodes: , and data . can be separated into . Then each of the shards can be replicated three time such that:
This way you can use the advantages of replication for scaling with the advantages of sharding for scaling.
(Basically) All the Databases
SQL
- Relational database storing normalized data. Data is stored as rows of a table.
- Has ACID guarantees because of transactions and 2 phase commits, and Write Ahead Logs
- (A)tomicity: Transactions are all or nothing. If there is an error in the middle of a transaction, the whole operation is rolled back
- (C)onsistency: Data is valid before and after. There is no data corruption or partial failures.
- (I)solation: No race conditions occur when transactions are concurrent with each other.
- (D)urability: Data is not lost even when the system crashes
- Having ACID guarantees makes SQL good for when data correctness is needed, as there is very little chance of data being corrupted, and if a transaction is failed, it will let you know, and it can be retried.
- Having these guarantees makes SQL hard to scale horizontally with multiple nodes though because it is hard to make these guarantees in a distributed system.
SQL is hard to scale horizontally
- Best thing you can probably do is single-leader replication.
- It is the default option (Postgres) to go to because it is so popular, tooling is good, and it is the industry standard for DBs
MongoDB (Document)
- Document data model
- As explained above, data is stored in hierarchical manner similar to JSON
- Can scale better horizontally, but does not offer the same ACID guarantees as SQL (guarantees BASE)
- Not really preferred to SQL because it has similar performance but not as standard practice.
Cassandra (Wide Column Store)
- Known as a column-family store. This means the data is stored as a table similar to SQL, but the data is grouped by columns instead of rows.
- Makes it easy to make queries for full columns instead of full rows
- Still considered NoSQL because it can have flexible data model
- Supports Multileader and leaderless replication strategies
- This is good for when you need higher write throughput because multiple nodes of the DB can accept writes.
- Uses last write wins strategy to handle merge conflicts.
- Good for when availability is very important, but because of LWW strategy, not the best for consistency Riak
- Basically the same as Cassandra, but it uses Conflict-Free Replicated Distributed Tokens (CRDTs) to resolve merge conflicts, which is more robust
HBase
- Another wide column data store
- Underlying infrastructure is Hadoop Distributed File System (HDFS)
- Uses Single Leader Replication for replication strategies.
Neo4J
- Graph database. When you have many to many relationships in your data and SQL becomes not optimal
- Pretty niche, but good for when your data can be naturally represented as a graph (e.g. social networks, knowledge graphs, etc.)
- Cypher query language
Redis
- Not technically a database, but it is an in-memory key value store.
- Essentially, it is a hashmap you can make exact match queries for for data that either is frequently accessed, or is esssential to be retrieved fast
Blob Storage
- BLOB (Binary Large Objects) storage is used for when you need to store data that is not exactly structured for a database (e.g. pictures, videos, audio, logs)
- It would not make sense to cram them into databases because it is note structured data with defined fields etc.
- Sort of like a file system to dump large files into.
- Also good for archives, as BLOB storage is cheap for large amounts of data.
- The reason you would pick a DB over BLOB storage is because of queryability.
- Typically, BLOB storage is used in the following manner:
- There is metadata of the file/object that needs to be stored (e.g. the date created, length, and key that will be used to look up the object in the BLOB store). This data can be stored in DB because it is structured, and it is needed so that we can find the location of the objects that we store.
- Actual object is stored in data bucket (e.g. S3)
- Presigned URLs
- Usually, if the user wants to download or upload the file to/from their client machine, it would not be a good idea to do it straight through the server
- This is because the whole object would need to be put into the request body, which is bad, and it can cause unnecessary load on the server
- To circumvent this, we use presigned urls, where a request is made to the server for an upload/download, and instead of performing the upload/download, the backend returns a presigned URL, that will give the user temporary permissions to upload/download to/from the BLOB storage directly
Networking
The OSI Model is the 7 layer abstraction that describes how data is generally moved between machines over the network.
The layers can be seen below:
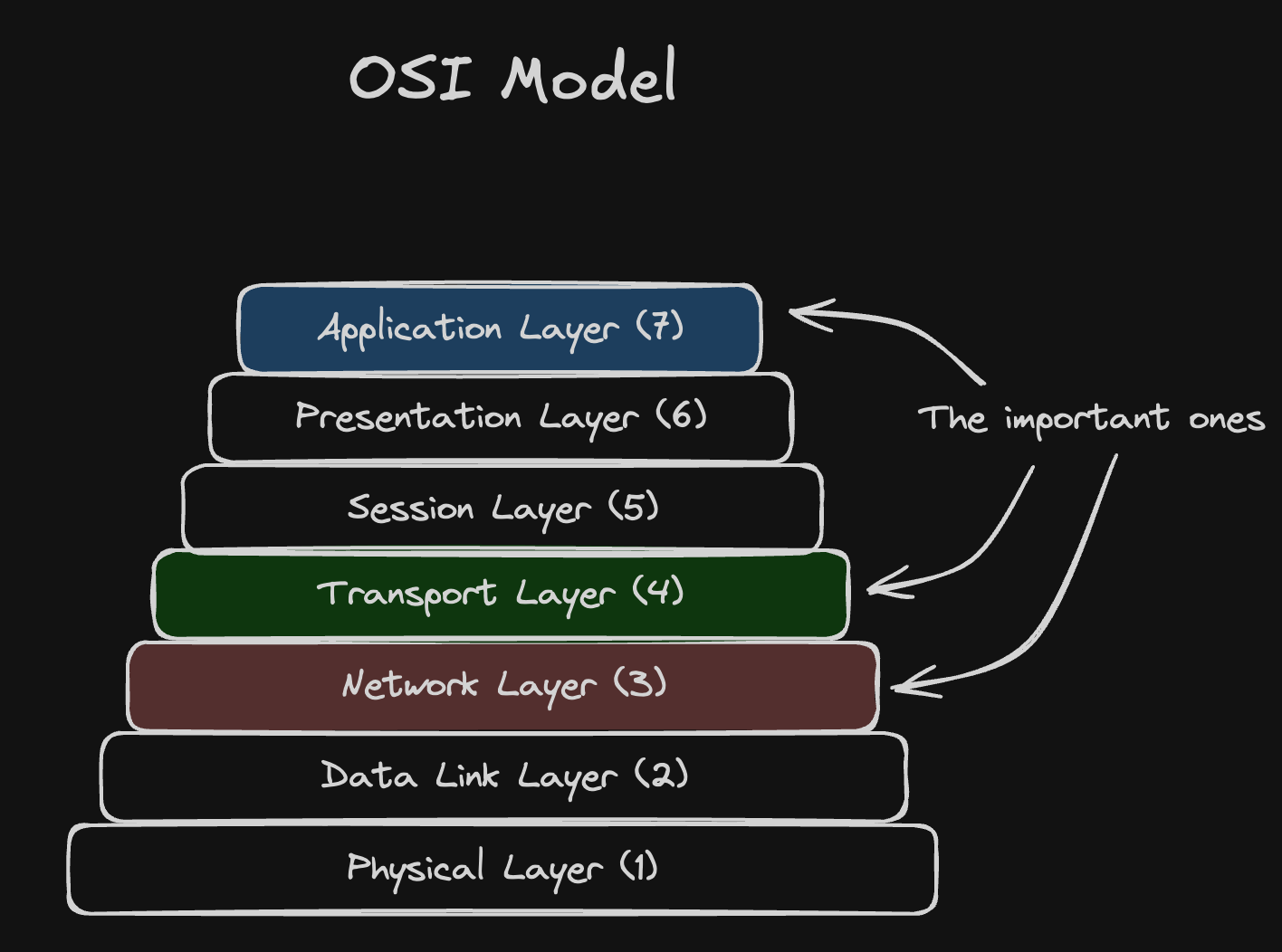
Each layer builds on the layer below it. For example, the Transport layer depends on the Network layer to be able to perform the routing of the data, and the Application layer depends on the Transport layer to have established a connection to send data over.
The main three that are important for system design are Network, Transport, and Application. Example of flow of communication can be seen below:
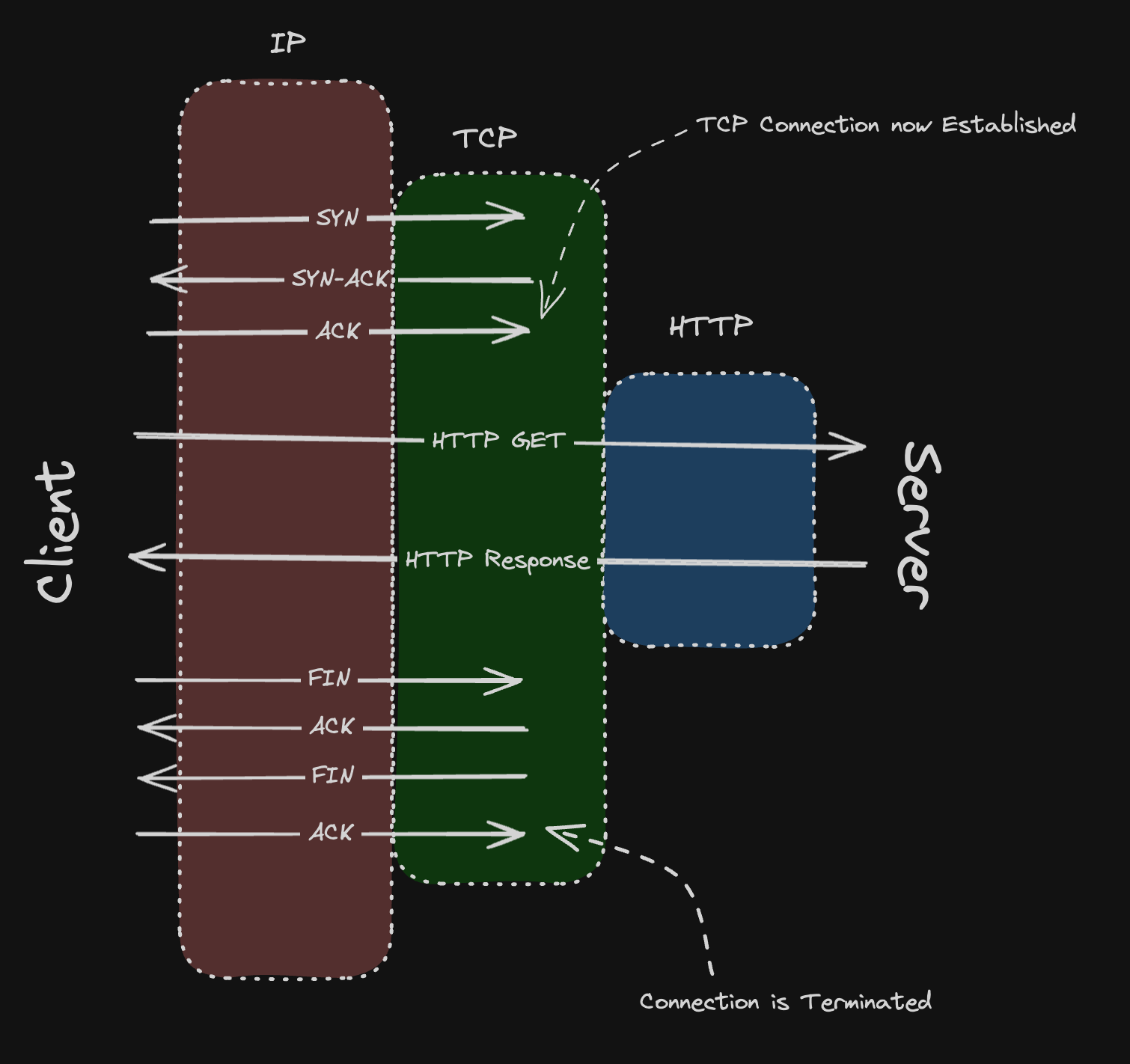
In the above image, you can see a three way handshake is first established to establish a connection. Then the request is sent and response is returned. Then the connection is terminated.
Each step has its own bit of latency.
Network Layer
This is where the Internet Protocol (IP) lies.
- IP provides machines with addresses that allows packets of information to be routed to each other. Like addresses of homes, and USPS needs them to be able to route packages to their destination.
Public Address vs Private Address
-
Public IP Addresses are addresses for machines that are known by all other machines in the world. This is needed for outward facing services/systems that need to accept requests/data from the public. These are usually IPv4 addresses because IPv4 was the standard initially and is supported almost universally
-
Private IP Addresses are addresses you assign to a machine to communicate between machines in your subnetwork. Use case might be nodes talking to each other as different microservices, or two servers needing to communicate to process a request. Used for internal communication.
Network layer is what is needed to be able to route packets of data from one node to another.
Transport Layer
Transport layer is needed to give context for the packets being sent node to node. It communicates the order of the packets as well as the source node of the packets to the destination node to be able to order the packets on the other side and be sure where it is coming from.
There are two main protocols to know in this layer: TCP and UDP
TCP
- TCP is the standard default protocol to use for establishing connection and ensuring data delivery in network communication.
- It guarantees delivery of packets as well as the order in which the packets are delievered.
- Ordering is done by giving each packet of data a sequence number so it can be ordered on the other side
- Delivery is guaranteed with many handshakes
- All the guarantees lead to an increase in latency and decrease in potential throughput though. It is not good to use this when latency and throughput is your main optimizing goal
UDP
- UDP is used for when you need to minimize latency and maximize throughput.
- Sample use cases of this include video conferencing, streaming, etc.
- Use when you do not care about the occasional packet loss because receving all packets of data is not vital.
- Does not offer the same guarantees as TCP, so it can have less latency.
Application Layer
This is where the Hyper-Text Transfer Protocal (HTTP) lives, a text formatted request and response model
Request:
GET /posts/1 HTTP/1.1
Host: host.com
Accept: application/json
User-Agent: Mozilla/5.0
The first line has the HTTP “method” (GET), the resource you are trying to access (/posts/1) and the http version (HTTP/1.1)
The remaining lines are headers, which are key value pairs that you can add to the request to give additional meta data to the destination node when sending the request over.
Response:
HTTP/1.1 200 OK
Date: Sun, 03 Aug 2025 12:34:56 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 292
{
"userId": 1,
"id": 1,
"body": "Stuff"
}
The response first line contains the HTTP version again + the response code (200 OK) signaling the outcome of the request being processed.
The remaining lines are again response headers, and after the headers, is the body of the response, which is the data the client requested.
The content-type header is a special header that allows for “Content Negotiation”
- The client tells the server what type of data it can consume/accept, and the server uses this data to determine what it can send to the client, and whether it can return the content the client can consume.
- This ensures backwards and forward compatibility for HTTP versions.
There are many models within HTTP
REST
- Representation State Transfer
- A way that we leverage HTTP protocol to make APIs
- We use HTTP methods and resources and map them to programming functions/methods to decide what action needs to be taken.
- Common HTTP Methods
- GET: Usually used for retrieving data
- POST: Usually used for inserting data
- PUT: Usually used for updating data
- DELETE: Usually used for deleting data
- These methods paired with a resource can define exactly what you want an API to do.
- Example:
GET /user/{id} --> USER-
In this example we use a
GETHTTP method matched with the/user/{id}resource, which defines an API that will return the user with the id{id}. -
We can have PUT, and POST, and DELETE methods associated with this resource to update an existing user, add a new user, or delete an existing user respectively.
-
- REST is considered the default/standard use case for API building, so unless there is some niche case, REST should be your choice of API modeling.
GraphQL
-
GraphQL addresses some limitations of REST
- If you need a bunch of information retrieved to load a page of your app, most likely you will need to make a lot of REST API calls to get all the data you need (e.g. profile pic, profile information, etc.)
- Each one takes time and resources, leading to increase in overhead.
-
Instead of making multiple requests to APIs to get all the information, GraphQL allows client to define exactly what data it needs from the server, and the server can go fetch exactly what the client needs all in the same request from whatever data source it needs to access.
-
It is often used for when the requirements of your system are changing, so you don’t need to constantly change multiple APIs.
gRPC
- Google Remote Procedure Calls
- It is seen as protobuf + services
- Protobuf: A way to define structures for data to be able to serialize the data into byte representation and eventually deserialize it back into original form
- Allows for efficient serialization into compact format
- It is good to use if you want to communicate internally from one micro service to another.
- It is not so good for publicly facing API endpoints because it is not natively supported in most browsers.
Server Side Events
- Everything before has been request + response pattern, where client sends request, server sends back response.
- SSE used for when server needs to push data to users as it happens (e.g. notifications, messages, etc.)
- SSE is a unidirectional connection from server ⇒ client
- It is used to be able to stream content from server to client.
- It is good for short lived running events (e.g. Chat apps for AI Chatbots)
- It doesn’t scale too well with large numbers of clients.
Websockets
- It is also a way for servers to be able to push data to clients, but it is bidirectional meaning clients can send events to server as well.
- This makes it good for any messages/chat apps
- It is more resource intensive than SSE, needing a lot of infra set up
- Web sockets are also stateful because they are connections that must remain open until user is no longer active, as the server needs to know the metadata of the connection(s) to clients it has established at the minimum.
Tip
Statefulness
State is the concept of the server remembering things over multiple requests. If a server remembers information about a request/event after it has been done processing, it is considered stateful. If the service processes each request/event independent of each other, it is considered stateless.
An example of a stateless API is a simple REST API to retrieve account information.
An example of a stateful API is a websocket API for a chat session, where information such as
userId,roomIdmay be stored.Stateless APIs are preferred to implement because when a server doesn’t need to remember information about previous requests, it is easier to scale, as requests can go to any server instance.
Stateful APIs are more complex to scale up because because if a server needs to know information about a user’s past request, the state has to either be replicated across all server nodes, or requests from each client in a “session” must go to the same server, each of which is harder to implement.
Scaling in Networking
- How can we get our system to be able to handle traffic at a global scale
Vertical Scaling
- A less technically complex but less practical way to handle scaling is vertical scaling. This just means beefing up the server you already have with increase in memory, CPU, disk, etc. to be able to handle more and more requests.
Horizontal Scaling
-
A more practical but also more technically complex way is to use horizontal scaling, which means getting more copies of servers and stuff to diffuse the traffic to multiple machines.
-
There are many things needed to perform horizontal scaling
Load Balancing
Placing a middle man between the client and the sever that takes the request from the client and routes the request appropriately to one of the servers based on current server traffic patterns (which server is the least congested with requests), server availability statuses (which servers are not crashed), etc.
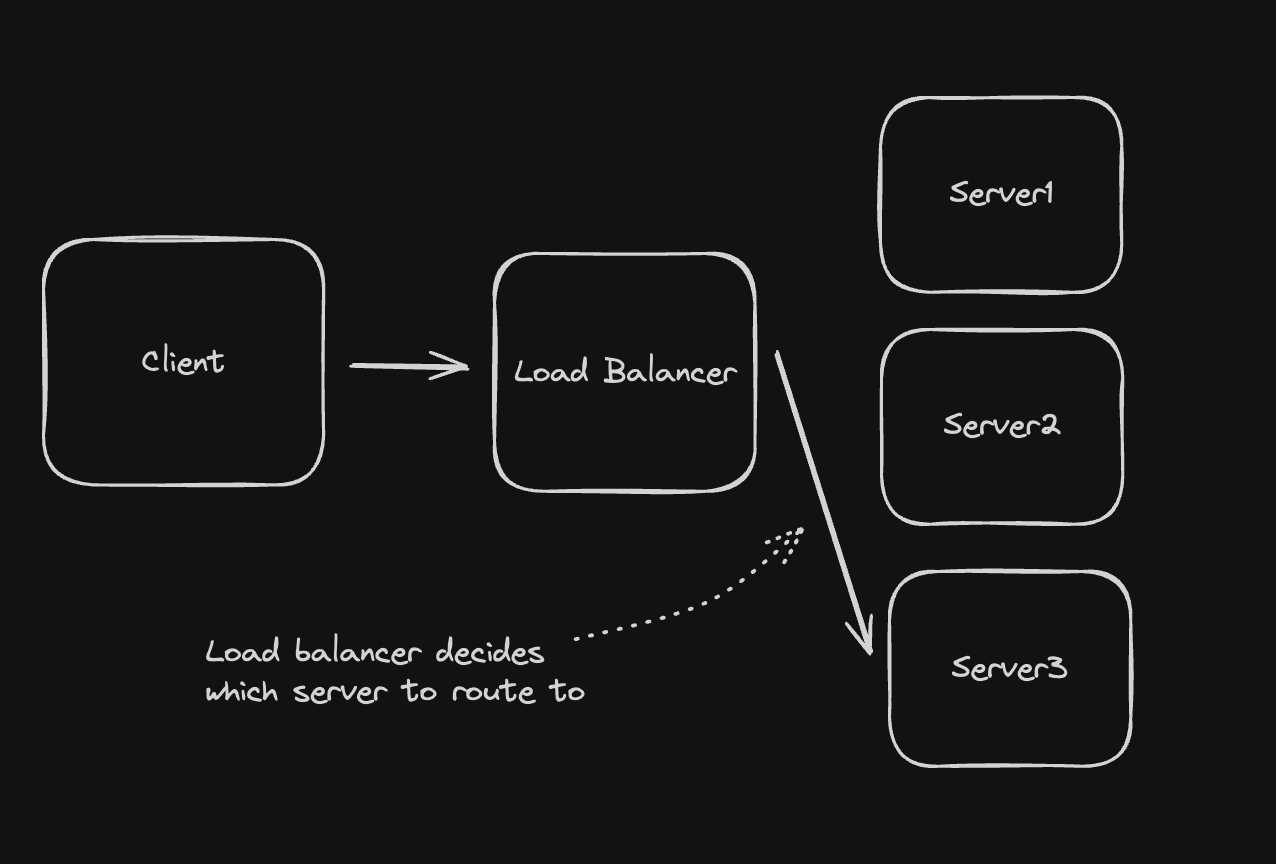
There are multiple ways the load balancer in the middle can be implemented: Client side Load Balancer, and Dedicated Load Balancer
Client Side:
- The routing is done locally from the client.
- The client must be aware of all clients, and performs the routing of the request.
- Because there isn’t any real logic in the routing like there is for dedicated load balancers, this minimizes the latency increase of the load balancer
- Not good for when you have a lot of clients, or if you need real time updates on server statuses.
Dedicated LB:
-
An actual load balancer receives the request from the client and performs the routing.
-
LB constantly sending health checks to servers to make sure they are healthy and can receive traffic, and performs a routing algorithm to route requests to servers:
- Round Robin
- Random
- Least Connections
-
There are also different levels the LB can live on: the network layer LB, and the application layer LB
-
Network Layer Load Balancer
- This sits in the network transport layer (TCP/UDP), and the routing is done based on IP addresses and ports.
- It is very low level, but very lightweight because it does not have to do deep dive into the contents of packets.
- Cannot make decisions based on the content of the HTTP requests
- Is compatible with any of the API models in the application layer since it is abstracted
-
Application Layer Load Balancer
- Sits at application layer.
- Allows load balancer to make routing decisions based on body of request
- More complex routing logic, so slower.
- Because it has content available to it, it can be used for throttling and rate limiting because you have access to auth tokens
Deep Dives
Regionalization
-
How do we deal with communication when traffic is coming from all different parts of the world? How do ensure optimal experience for users no matter where in the world they are located.
-
As discussed before with data, this can be done with partitioning of data and replication of data across multiple nodes across the world to ensure data is close enough to most of its users.
-
It is good to try to find natural partitions in data to spread data across. For example, with Uber, a user in Seattle will not need any data regarding drivers in London or Austrailia.
-
Colocation of Data:
- You want to keep your data and your server close together geographically to ensure you aren’t unecessarily adding latency where you don’t need to.
- Also can use a CDN.
- Cloud Distrbution Network, is like a globally distributed cache, where data can live for some time if it was recently accessed
- When a user wants to access the data again, it will make a request to the CDN as if it was the server first, and if the CDN does have it, it will return the data, but if it doesn’t it will redirect the request back to the original server
Failure/Fault Handling
-
A key to remember in all System Design interviews is that unexpected faults and failures are going to happen, so you need to be able to handle them.
-
How can we handle network requests that fail at network level? This is different from getting a server or client error code from the request. This is when the packets are lost in transit, the server never receives the request etc.
-
Timeouts
-
We have to introduce timeouts to the client, so that the request the client makes eventually times out if no response is given within a certain period of time.
-
Needs to be long enough to give the request the chance to be processed, but also should be short enough so we aren’t unnecessarily waiting for something that won’t happen.
-
-
Retries
- With timeouts, we want to give the request multiple efforts to succeed in case we failed due to a transient error.
- We allow client to retry some amount of time before actually erroring out.
- We use exponential backoff as a retry strategy, which means the interval between each retry increases after each retry.
- This is to not overload the server with retry requests, and because if the 2nd or 3rd retry won’t work, it is likely that the error is not transient, so no point in retrying so fast.
- We also introduce a random +/- to the retry interval (Jitter). This ensures if requests are clustered together, their retry attemps won’t also be clusterd together. More evenly distributed traffic pattern.
Cascading Failures + Circuit Breakers
Given the following design component:
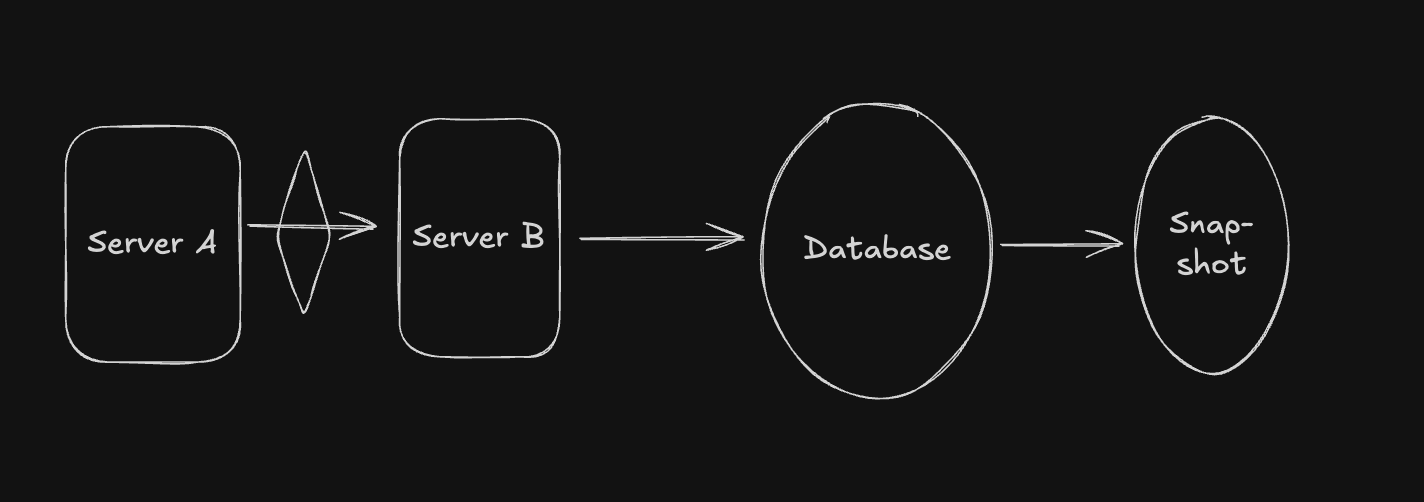
Let’s say the DB is at 50% capacity because of the snapshot it is producing. This means half the requests server B makes to DB will fail, and because of this, server B will make retries of these requests to the DB.
The retries also fail, which means server A is receiving failure responses from server B for its requests, so server A will also make retries.
With server B handling its own retries as well as server A’s retries, it will become overloaded and may crash.
An engineer may look at this and think server B is the problem, and try to restart it, but won’t find the issue because it is a cascading failure, originating from a different component.
We can introduce a Circuit Breaker to pause the sending of requests from server A to server B until the root cause is found.
The circuit breaker will automatically pause the requests sent from A to B if the failure rate of requests breaches a certain threshold, and waits a certain period of time. Then, it checks again to see the status of server B, and once it is healthy again, it will resume requests.
This will prevent us from having cascading failures, as we won’t pull down the whole system, makes sure we aren’t unnecessarily using up resources, and allows for failing system to recover.
API Design
What are APIs
APIs are a mechanism that allows components of software to communicate with each other with a set of definitions and protocols.
Types of APIs
REST
- REST is API Protocol that is built upon standard HTTP requests and tools (e.g. PUT, POST, GET)
- There are two main components in a REST API request: The resource and the HTTP method
- Resource
- this defines the data that is being acted upon.
- Example: if you have a ticket booking app, one resource could be
events. Could also beuserortickets - Mainly defined by the core entities of your system
- HTTP method
- This defines the action that you want to take upon your resource
- Use
GETto retrieve information about resource,PUTto update a resourcePOSTto publish a new instance of a resource, etc.
Together, the API request looks as follows:
GET /events/{id} <-- gets the details of an event with given ID
GET /events/{id}/tickets <-- gets the tickets for a given event
POST /events/{id}/bookings <-- posts a new boooking of a ticket for an event
- As you can see, resources can be nested within one another, with tickets and bookings being under events.
Inputs to REST APIs
- Path Parameters
- These exists within the URL, and define the specific resource you want to work with (e.g.
idinGET /events/id)
- These exists within the URL, and define the specific resource you want to work with (e.g.
- Query Params
- Also exist in the URL, but help to filter out resources and finetune a query
- Example:
GET /events?city=LA&date=2025-08-11
- Request Body:
- Where the data that you want to insert lives.
Response to REST API Calls
- Uses standard HTTP codes for responses
- Combines Response code with response body for the total response
- Important Codes:
- 2XX - Successful request processing
- 3XX - Redirect response
- 4XX - Client error (e.g. bad request, authentication, rate limited)
- 5XX - Server error (i.e. exception on server side)
GraphQL
- GraphQL is a different type of API protocol that was meant to address shortcomings of REST APIs.
- Main problem with REST: If you wanted to retrieve a bunch of different information from varioues resources, you would have to make an API call for each piece of information, and if you wanted to add more information to your data and be able to retrieve it, you would probably need to create a whole new API endpoint.
- GraphQL allows client to form a request that tells the server exactly what it needs from the server — nothing more, and nothing less.
- Example of REST vs GraphQL:
query {
event(id: "123") {
name
date
venue {
name
address
}
tickets {
price
available
}
}
}
v.s.
GET /events/123
GET /events/123/tickets
GET /venue/456
GraphQL formulates one query to retrieve the event details, the venue it is being hosted at, and the tickets that are available.
Remote Procedural Calls (RPC)
- RPC is another type of API that is mainly good for intra-service communication (i.e. when you want two of your internal services within a system to communicate with one another)
- You have to define inputs and outputs with proto files so that they can be byte serialized
- Makes for efficient calls and request processing.
- It is not good to use for externally facing API endpoints because it is not widely supported by interfaces clients would use (e.g. web browsers, mobile apps, etc.)
Follow Up Topics
Pagination
- This is for dealing with API requests that retrieve a large amount of data or a lot of records
- You don’t want to send all records over the same network connection all at once.
- Two types: Page base v.s. Cursor Based
- Page Based
- Most common one and most likely one to use in system design
- You use query params to define the amount of items per page and which page you want
- e.g. with
GET /events?page=1&limit=25, you get items 1-25
- Cursor Based
- Use query params to tell you which item to start at and how long the page is
- e.g. with
GET/events?cursor=123&limit=25, you get items 123-147
Security Considerations
- Authentication vs Authorization: Authentication verifies identity, by proving user is who they claim to be. Authorization verifies the permissions of the user to make sure they are allowed to perform the action they are trying to.
- Example: For ticketmaster, authentication makes sure the request is coming from johndoe@example.com, and authorization makes sure that johndoe@example.com is allowed to cancel this booking.
Authentication Implementation
- API Keys
- These are long randomly generated keys generated acting like passwords for users that get stored on some database.
- Each client makes call to API with API key, and API first searches for this API key in the database to verify who the client is making the call
- This entry in the DB will store information about the actions this user can take, the throttling/rate limit for the user, etc.
- Good for service to service communication
- JWT (JSON Web Tokens)
- JWT store all information about the user making the API calls, and it is also sent with all the information about the user, and their permissions, etc. in the token itself
- All happens once user has logged in.
- Good to use JWT for client to server calls because good in distributed systems
Role Based Access Control
- Similar to IAM roles in AWS.
- Systems have different types of users that require different actions in the system
- E.g. A customer on ticketing app needs to be able to buy tickets for events and stuff, but an event manager needs to be able to post events onto the app
- Roles are assigned to users, and server will verify the user has the proper permissions to perform this action.
Rate Limiting/Throttling
- Prevents abuse of an API endpoint by limiting the amount of requests a user can make to the endpoint in a given time period (usually minutes or seconds)
- No malicious attacks or accidental overuse.
- Common strategies
- Per User Limits: Limits amount per authenticated user
- Per IP limits: Limits amount per IP address making request
- Endpoint Specific Limits: Limits amount for all users on specific endpoint
- Use
429error code. The rate limiting usually happens at API gateway level, not directly at server/API level.
Numbers to be Aware of
Modern Hardware Limits
- Modern compute is really powerful
- e.g. there are compute servers you can use with up to 4 TB of Memory or with 512 GB of RAM and 128 vCPUs
- This means apps that would have traditionally required distributed systems could now be handled by one server if needed
- Also same modern increases in disk size.
- Note: event with these modern advances, you need to be able to communicate to interviewer how you can effectively horizontally scale your system
Caching Numbers
- In memory caching can handle up to TB’s of data, and can access the data in 0-1 ms (can be sub millisecond level as well)
- Main numbers:
- Latency:
- Reads: < 1ms
- Writes: 1-2 ms
- Throughput:
- Reads: > 100k requests
- Writes: > 100k requests
- Storage: ~ 1 TB
- Latency:
- When to consider sharding for cache
- When you’re exceeding storage limits, or need sustained throughput of > 100K requests or sustained < 0.5 ms latency
Database Numbers
- Postgres and MySQL can usually handle TBs of data with millisecond response times
- Main numbers:
- Storage: ~ 64 TB
- Latency:
- Reads: 1-5 ms for cached data, 5-30 ms for uncached data
- Writes: 5-15 ms for transaction commit latency
- Throughput:
- Reads: 50k TPS
- Writes: 10-20k TPS
- If you think you will exceed any of these numbers in your system, then you will consider sharding
- Also consider sharding for fault tolerance/network tolerance, as well as if you need to make geographic considerations
Application Server Numbers
- Servers have increased in performance a lot in modern times
- Numbers to know:
- # of concurrent connections: >100k
- CPU cores: 8-64 cores
- Memory: 64-512 GB of RAm
- Network Speed: up to 25 Gbps
- If you see CPU utilization/Memory utilization reaching >70-80%, or network bandwidth reaching threshold, need to shard/horizontally scale
Message Queue Numbers
- Process millions of messages with single digit millisecond latency
- Numbers:
- Throughput: up to 1MM messages per second
- Latency: 1-5 ms
- Message Size: 1K=kB - 10Mb/message
- Storage: 50 TB of storage
- Retention: Weeks - Months of data
- If you are reaching theshold on any of these numbers, or if you need geographic redundancy, look to shard.
Common Mistakes
- Do not be too eager to shard/horizontally scale. Don’t need to overengineer the system if it is not needed
CAP Theorem
What is CAP Theorem?
- CAP Theorem is the idea that for a database, in a distributed system, you can only have two of the following properties
- Consistency: The idea of data being the same across all instances of the databases. All users see the same data at the same time
- Availability: Every request to the database will get a valid response
- Partition Tolerance: System works despite network failures to database.
- You will always choose Partition Tolerance, because network failures are inevitable in distributed systems and system always needs to handle them, but you will need to choose between Consistency and Availability.
What makes availability and consistency conflicting?
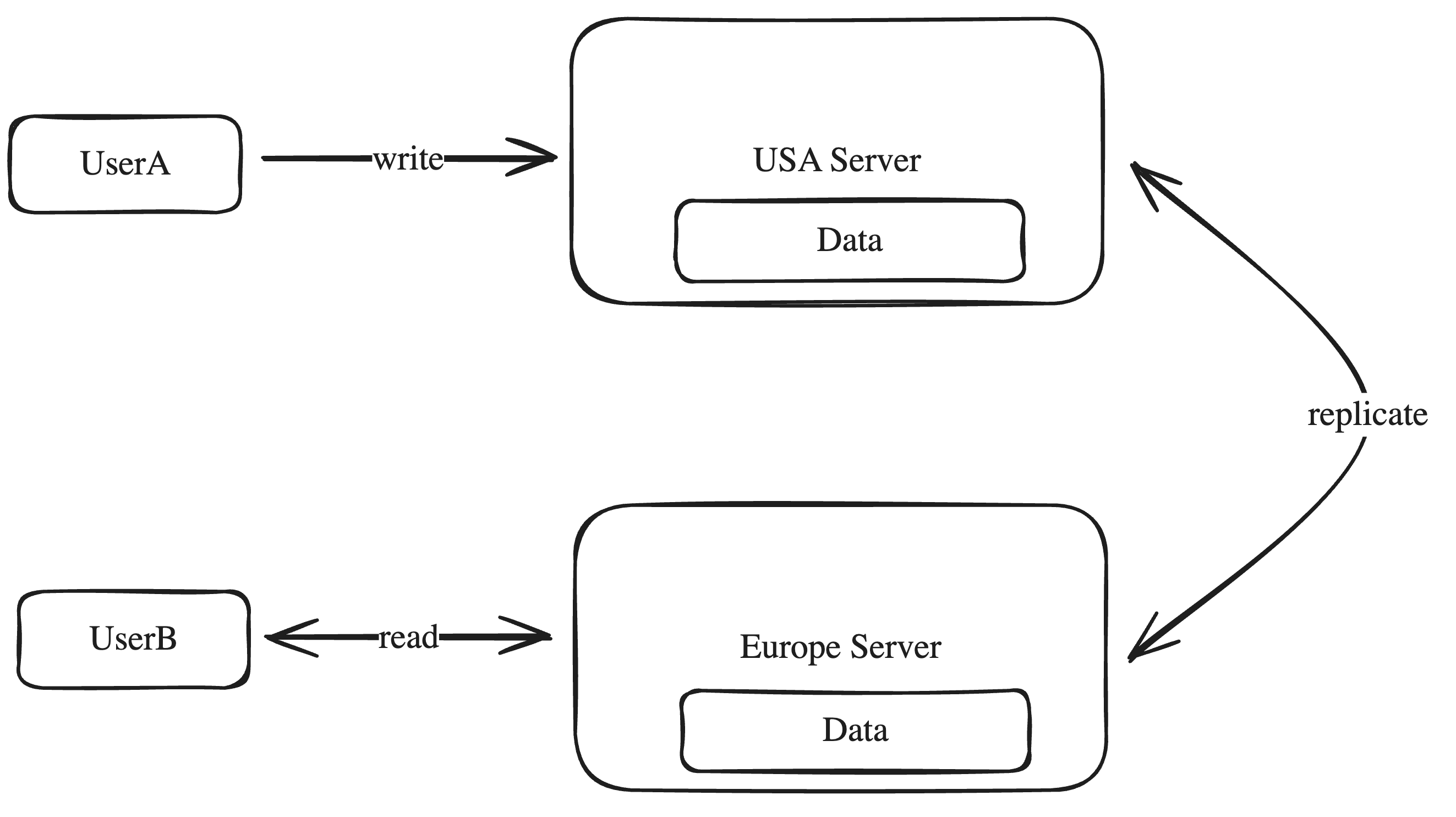
- If we have a system as above, where there are two databases that can take queries, and stay synced with each other, there are two possibilities:
- Consistency: after each database transaction is committed, the database sync happens right away and happens before the request is returned a response so that DB instances are always in sync. However, if one of the DB instances goes down, and the other DB is taking requests, it will have to return failure responses because it cannot replicate the data to the other DB instances, so this meanse the DB is not available.
- Availability: The database sync happens asynchronously at periodic times and when we process read requests, we have the possiblity of returning stale or out of date data, but each request will be given a response.
Use Cases
Use Cases for Consistency
- You will need consistency when it is vital for all the users to see the same data at the exact same time.
- Examples:
- Ticket booking app: You need to make sure every user sees the same status about certain tikcet/seat of an event because we cannot have users book the same seat/booking.
- Inventory System (i.e. Amazon): If there is 1 left of an item in the inventory, we have to make sure multiple users don’t successfully order the last item.
- Financial Systems
Use Cases for Availability
- For almost ever use case, availability is more important than consistency. It is more important in most other use cases that the system is still functional and online.
- Example:
- Social Media Service: It is not too important that we see the most accurate amount of likes on a post in real time. It is better to make sure there is a value there that was once accurate
- Streaming Service: You don’t need exact accurate information about ratings, reviews, etc.
Implementation in System Design
Implementing Consistency
- If you have multiple instances of a DB, you need to implement distributed transactions to make sure all DBs are in sync. (e.g. 2 Phase Commit)
- If possible, you could limit DB to one single node, but only if all data will fit in the single node (e.g. on scale of 1-64 TB)
- Need to accept higher latency to ensure consistency
- Example tools:
- Postgres/MySQL/Any other RDBMS
- Spanner
Implementing Availability
- You should have multiple replicas
- Implement Change Data Capture (CDC) for eventual consistency
- Example tools:
- Cassandra
- DDB
Other Topics
- Sometimes in a system, there are different components where there are different requirements. This could make it so one component requires consistency, but other components require availability.
- Example: bookings for a ticketing service needs to be consistent, but other aspects like metadata about venues may not need to be consistent. Maybe better to be available.
- Different Levels of Consistency:
- Strong Consistency: All reads reflect the most recent writes
- Causal Consistency: All related events appear in right order.
- e.g. If a user makes a comment, and another user replies to the comment, the original comment must show up before the reply
- Read your writes consistency: Users own writes are always reflected in reads.
- e.g. If a user makes an update to their own profile, they should be able to see the update right away.
- Eventual Consistency: eventually, all the database instances will become in sync and have the same data
Key Components/Technologies
Redis
Redis is a very versatile technology that has many different use cases. It is also quite simple to understand in its implementation.
What is Redis?
- It is a single threaded, in memory, data structure storage server.
- Single Threaded
- No multithreading is implemented, so all requests are processed one at a time per instance, making it simple to understand
- In Memory
- All data exists in memory, making accessing the data very fast, but it also makes it not durable.
- Data Structure Server
- Values inside redis can be data structures.
Infrastructure Configurations
Different configurations have different implications
- Single node
- A single node of a redis server exists, and it will back up the data in the redis server to disk periodically, so that if the instance goes down, then it can back up properly
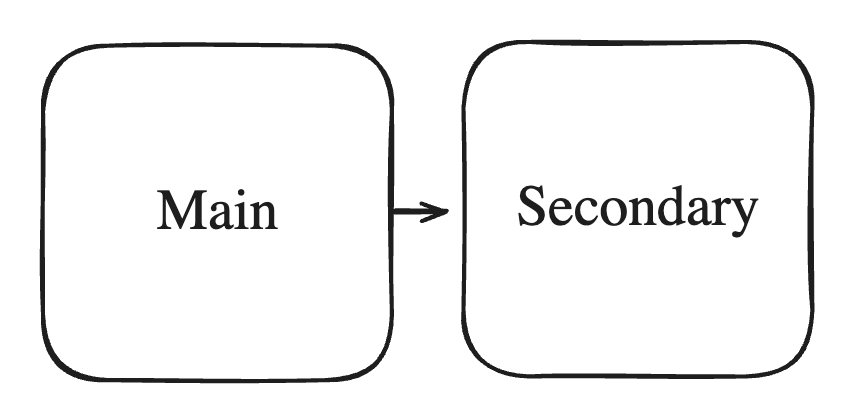
- Replicated Node
- You can add a read replica of your redis server to ensure high availability of the redis server
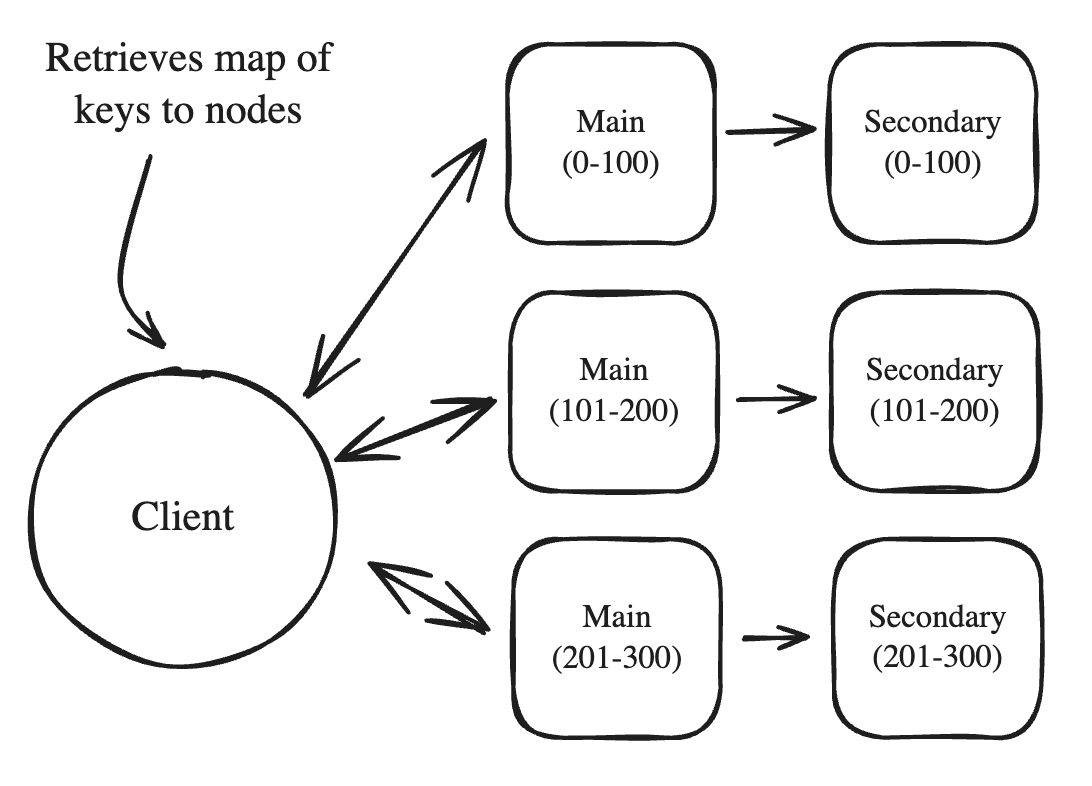
- Cluster
- How Redis implements partitioning/sharding.
- The keys are hashed and can fit into a “slot”/“bucket” that it gets assigned to, and the client is aware of all instances
- Clients have maps on their side mapping slots to nodes so the entry can go to right node
- How you structure your keys can determine how your redis system will scale
- Hot Key Problem
- If one key is accessed a lot more than other keys, we will run into issue where one node of the redis cluster will get the bulk of all the requests.
- This can be solved in a couple of ways
- Add read replicas to distrbute the read requests
- Store same data in different modifications of the same key (e.g. appending random digits/chars to the end of the key so that the hash will assign it to different slots)
Uses of Redis
Using it as a Cache
- The most common use of Redis
- Service checks the Redis cache for entries before it tries to request the database. If entry is found, it will return the entry. If it is not found, query to database is made
- Makes frequently accessed data faster to access.
- Only good if you can tolerate some staleness of data.
- Need to consider expiration policy:
- Can have a Time-to-Live (TTL) policy, where entries in the cache will be removed after some time.
- Can have LRU policy. When cache becomes full, the least recently used entry will be removed.
- How long can you expect the data to be valid?
- Also, if you update data, the cache entry will be invalid, so it needs should be cleared
Use Redis as a Rate Limiter
- Use when you have an expensive service you don’t want to be bombarded with requests.
- Store a key value pair where the key can be the user key or something to keep track of who is making the request, and you can make sure they are not sending too many requests to your service.
- Set a time to live on the key value pair, so that after a minute or so, it expires and user can make requests again.
- It does not scale that well when you have a lot of users because of the fact that Redis is single threaded.
Redis Stream for Queue/Async Processing
- Redis has a mechanism called Redis streams that offers similar functionalities as a Kafka queue.
- Items (which have their own key value pairs) can enter a Redis stream, and Redis has consumer group concept that can assign each item sequentially to a “worker”, and this worker will perform the async processing.
- Consumer groups allow for you to keep track of each item that gets processed in the Redis “queue”
Redis for Pub/Sub
- Redis has Pub/Sub capabilities built in that can be used for when you need servers to communicate with each other.
- Example is when you have a chatroom app, and each user in a chat room is on a different server. Each server can just publish to Redis, and other servers can subscribe to the Redis instance, and retrieve the messages to allow for communication between server instances.
- Allows for a centralized registry for messages to be routed where they need to be routed.
Warning
Redis Pub/Sub is fast, but it is not durable. It has “only publish once” design, so if subscribers are offline when message is published, it will miss the message forever. Redis Pub/Sub is not good if you want delivery guarantees, message persistence, or ability to replay missed messages. If you need these, use Kafka.
Redis as a Distributed Lock
- Used for when there is contention in an application (e.g. a booking in a ticketing app)
- If someone is in the process of reserving a seat for an event, you can give them a lock to make sure no other user makes that booking at the same time.
- Use Redis atomic increment with a TTL or expiration time.
- If the atomic increment returns a value of 1, then you have acquired the lock, but if the value is > 1, then someone else has the lock and you need to wait.
- When you are done with the lock, the key value should be deleted, so other people can acquire the lock.
- Redis has other distributed lock algorithms with fencing tokens as well.
ElasticSearch (ES)
ElasticSearch is a common tool used to implement distributed search engine for systems
What is Search?
- Search has many components to it:
- Criteria/Facets: The query that defines the data that you want to retrieve
- Sorting: Sorting the results based on specific fields
- Results: The retrieved data
Basics of ElasticSearch
-
ES works with indexes and documents
- Documents are JSON blobs of information
- Indexes are collections of documents that you would like to perform search on
- You can define a mapping on an index, which basically defines the structure of the data you want to be retrieved when performing the search. Useful if you do not want all the data of each object when performing search
-
ES provides a RESTful API to allow users to interact with it and perform search, sort, insertion etc.
-
Search API
- You can query for data using JSON object that defines the criteria of your search with a GET request to retrieve the data.
- Also returns additional useful metadata of the search operation that can be useful
-
Sort API
- Similar to Search API where you define how you want to sort using JSON object and use GET request to retrieve the data in the order you want.
- Can define how to sort the data with custom scripts in ElasticSearch own scripting language
- You can also sort based on a relevance score that ES defines, which is computed in a similar manner that TF-IDF is computed.
-
Pagination
- For when your search can return too many results for one http request.
- Stateful vs Stateless pagination both implemented in ES
- Stateful means that the server keeps track of something (similar to a cursor point) to know from which item to start retrieving the next page of data
- Stateless means the point to start at is defined in the request query
- ES has Point in Time pagination, which allows you to perform pagination on a given snapshot of the data at a given time. This handles the case where indexes are being update constantly, which could cause pagination to miss some results from being shown.
-
API for putting data in
- You can use a POST request with the request body containing the index you want to create in your ES cluster.
- You can also use a POST request to define a mapping for your index. This is optional, but it makes performance better, as ES is not inferring types on the data, and all data is defined and organized correctly.
- You add documents to the index using simple post requests
- Each query and returned object has a versionId associated with it. This is to handle concurrency in ES. You add/update data with a versionId in the request as well, so that if someone else is also making an update to the same data, the two requests don’t perform conflicting operations.
How to use ElasticSearch in System Design
- Use ES in your system design interview if you see that the system that you are designing requires a complex search functionality that could require more than a simple search query to your database can handle.
- Do not use ES as a primary database. Main reason is it does not have the durability and availability guarantees that standard databases need in a proper system.
- Usually, it is connected to a primary database using some sort of message queue (e.g. Kafka), where the change data capture (CDC) of the database is sent through the queue to ES to periodically sync the ES cluster with the primary DB.
- This is done asynchronously, so ES cluster usually always a little behind the DB, but eventually consistent
- Need to be able to tolerate eventual consistency to use ES.
- Best with read heavy workloads.
- Works best with denormalized data, where all data is flattened out.
Deep Dive on ElasticSearch Internals
-
ElasticSearch operates as a high level orchestration layer that manages APIs, distributed systems, coordination, etc. and uses Apache Lucene as the high power low level search system
-
ElasticSearch operates and orchestrates using a cluster of nodes architecture, where each type of node specializes in a different functionality to orchestrate the whole system
- Master Node: Usually only 1 in a cluster, and this handles creating indexes, cluster level operations (e.g. adding/removing nodes), etc.
- Coordination Nodes: Taking requests, parses them, performs query optimization, and sends them to appropriate nodes. Because they take in all requests and route them, need heavy networking requirements
- Data Nodes: where all the documents and indexes are stored. Because they store all data, need a lot of them, and each one needs high I/O requirements and disk space
- Ingest Node: Where all the documents enter to be ingested/processed into the system and sent to Data nodes.
- ML Node: The node that specializes in any high Machine Learning workloads. Because it performs ML workloads, most likely needs GPU access other nodes don’t need.
-
Each node has different functionalities, so each node will have different hardware requirements. How is ES distributed?
-
Each index will have sets of shards and replicas.
- Shards perform partition of data into different nodes to allow for increased amount of data to store and also increase throughput
- Replicas of shards are usually read only backups of shards to enable higher throughput for read requests mainly.
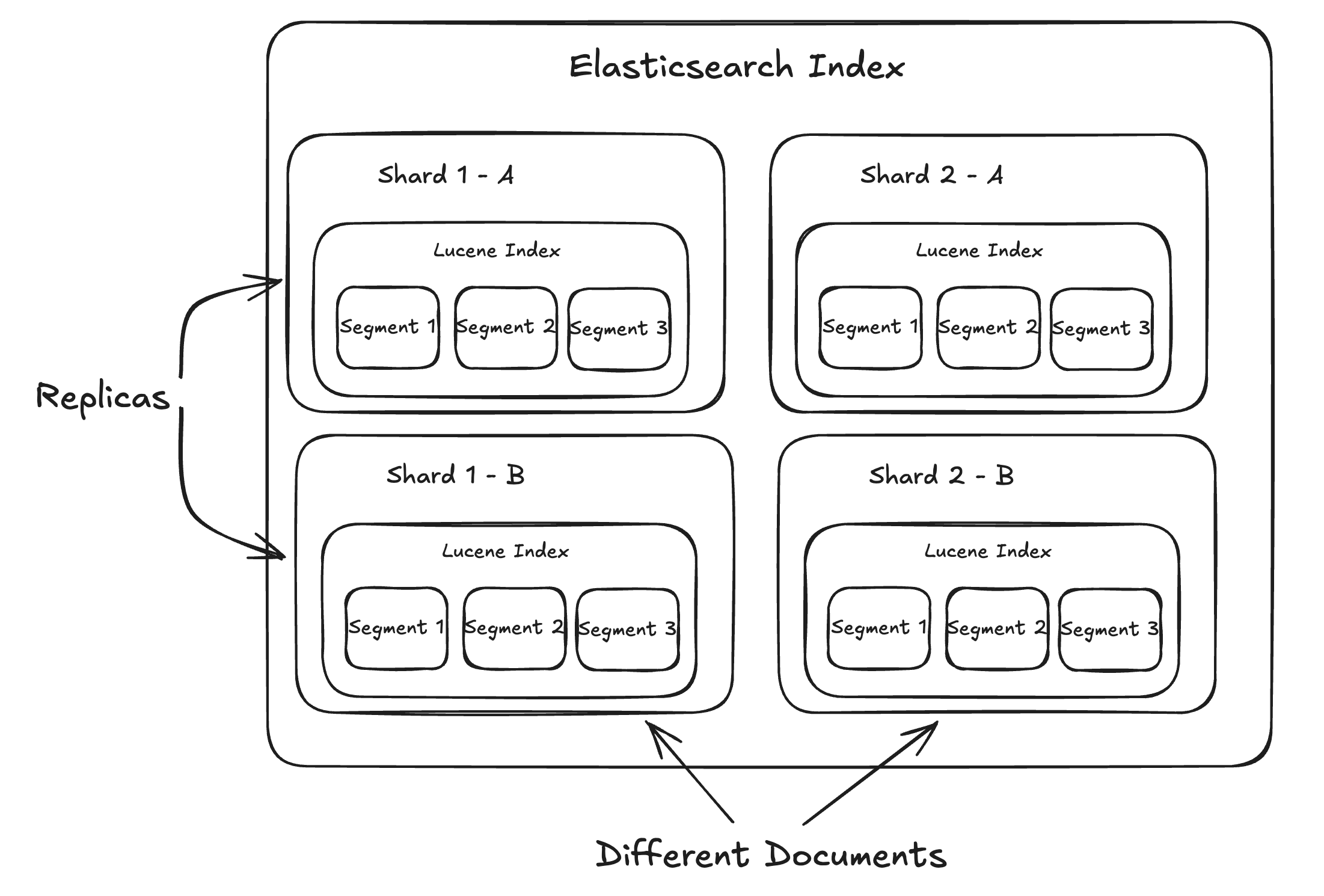
-
Each replica of each shard has its own Lucene index stored inside of it to perform the search functionalities.
-
Each document is stored in a segment of the Lucene index. A segment is an immutable container of indexed data
-
Documents are first sent to segments in a Lucene index, and these segments are then flushed out to disk in a batch write operation.
-
Segments can be merged together when they become too numerous on disk.
-
Since segments are immutable, to perform updates and deletions, we perform soft deletes (i.e. marking the data for deletion) on the old data, so we do not recognize it as data anymore, and we perform an append of th enew data we want to write if we are updating.
-
Immutable property of segments makes caching and dealing with concurrency a lot easier, as you don’t really have to worry about two users modifying the same data. Also, since its basically append only architecture, writes are a lot faster.
How to Make Search Fast?
-
Lucene/ES makes use of inverted indices to make search faster.
- Inverted indexes takes the text in the document and uses them as keys for the index. If the document contains that word in its contents, it will add the document id to the list for the key.
- You can go further with the keys of the index by adding other forms of the word as keys as well (e.g. using lemmatization, synonyms, plural version, etc.)
-
Sorting is made faster by implementing a column based storage, so that you do not have to query all the data of each document to perform sorting/filtering.
-
Coordination Nodes also perform optimized query planning in the queries it gets so that queries can be processed in the most efficient way possible.
API Gateway
- API gateway is a thin layer that sits between user and all the services that your system may have.
- In a large system, you may have many services your user would have to interact with, and it is not feasible to have clients know endpoints to all services within your system and know which one to hit for each request that is made
- API Gateway receives all the requests for you and performs the routing for client so client just interacts with the API gateway endpoint, but are able to interact with all services in your system still.
- API gateways also perform a lot of middleware functions that need to be done to hit an API endpoint successfully. This includes:
- Authentication
- Rate limiting
- Input validation
- Logging
- Allowlisting/whitelisting
- etc.
- API gateway can connect to other services to do this (e.g. an Auth service or redis instance for rate limiting)
- Steps for API gateway
- Request validation
- Make sure request sent is valid. If invalid, immediately reject
- Run middleware operations
- e.g. Authentication, rate limiting, etc.
- Route request to correct service
- This is done with a routing map stored on API gateway. Maps API paths to service endpoints
- Service processes the request and returns back a response from the processing. Once this is done, the response may need additional transformation to be able to be processed by the client.
- After request is processed and response is returned, API gateway can optionally cache the response for faster response times on later calls to API.
- Request validation
Scaling API Gateways
- API gateways are usually stateless, so to scale them to be able to handle more requests, horizontally scaling is usually used (e.g. adding more hosts/instances)
- Put API gateway instances behind a load balancer, or have Load Balancer as a feature in the API gateway itself.
Examples of API Gateway
- Managed Cloud Services: AWS API Gateway, Azure API management, etc.
- Open source: Kong API Gateway.
When to use API Gateway in Interview
- Use when you have a microservice type architecture. It is not needed when you have a simple client to server architecture. May only need a load balancer
- Do not spend to much time on the implementation of API gateway when using it. Place it down and move on.
DynamoDB (DDB)
- DDB Data Model
- Data is grouped into tables, which are collections of related date
- Items are the individual records of data. Similar to SQL rows,
- Attributes are the properties/fields of each item
Properties of DDB
- DDB is schemaless
- This means rows are flexible in the attributes that they have.
- Some rows include some fields that other rows may not have.
- Pros: Flexible data schema that doesn’t require migrations, and you only pay for what you store, no need to pay for extra space for nulls/undefined
- Cons: Your data validation has to be handled by the application layer (e.g. handle missing attributes, extra attributes etc.)
- Indexing
- DDB makes use of two keys: partition key, and sort key
- Partition key is the unique identifier that determines the physical location that the item should go to. Uses consistent hashing for this
- Sort key is an optional key that is used to enable range queries of data in DDB partition. Sort keys stored using B-trees to enable sorting and range queries.
- Primary key of DDB item is
{primary_key}:{sort_key} - Examples
- Chat App (Messages):
- Primary key may be chat id, so all data related to the same chat are in the same geographical location.
- Sort key can be message id, which is always monotonically increasing to serve same purpose as timestamp
- Social Media (Posts):
- User Id can be the partition key so all data related to same user is in same partition
- Post Id can be sort key to perform same function as timestamp.
- Chat App (Messages):
- Global Secondary Indexes (GSI) and Local Secondary Indexes (LSI)
- For when you want to efficiently query for data with other keys other than primary and sort key.
- GSI acts as another primary key. You can make another field a GSI, and it will basically create a replica of the data using this key as the primary key for partitioning. You only need to project the data that you need though, to be space efficient.
- LSI act as another sort key, and same process occurs. You create a replica B-tree for the data with this key as the sort key, but you only project the data/fields that you need.
How to use DDB
- To perform DB queries, there are native SDKs in all programming languages that can be used to perform DDB queries.
- DDB has the ability to perform transactions similar to MySQL as well if you want to enable strong consistency
DDB Architecture
- DDB Scales using consistent hashing, as explained before. This is how it is able to efficient partition data into the shard it needs to
- Fault Tolerance
- By default, uses single leader replication strategy, where one DB gets written to, and all replicas get asynchronously updated to be in sync with leader.
- This means relies on eventual consistency
- You can enable strong consistency as well, but you will sacrifice availability and latency.
- Advanced Features
- DynamoDB Accelerator (DDB)
- An implementation of an in memory cache that sits in front of the DB for more frequently accessed data.
- So you don’t have to create a Redis instance in your server.
- DDB Streams
- Real time streaming of the Change Data Capture (CDC) of the DDB that can be sent to lambdas to be processed, or can be sent to ElasticSearch instance to sync search platform data with the DB.
- DynamoDB Accelerator (DDB)
When to use DDB
- You can use DDB almost every time that you can use PostgreSQL or MySQL, because it has options for Strong v.s. Eventual Consistency and Transactions vs No Transactions now.
- You should not use it if your query patterns have many complex joins and complex sub queries, as DDB cannot handle as well as PostgreSQL.
- Should not use if you have transactions that involve multiple tables
- Should not use if you have complex data model you need to store.
Kafka
- Kafka is a distributed event streaming and message broker platform that is mainly used for message queue systems or event streaming systems
Motivating Example
-
Imagine you are running a website that updates clients with real time updates for games happening in the world cup.
-
You have a producer that is publishing the events to a queue, and consumers that are taking these messages and processing them and sending them to the clients.
-
A server with a simple queue system will work for the normal World Cup scenario, but what happens if you want to scale this system to be able to track over 1000+ games at the same time and send events for all of these games.
-
Problem #1: Too many events can lead to the server with the queue running out of space
-
Solution #1: The easiest way to fix this is to horizontally scale your queue server by adding another server with another queue to be able to handle messages
-
Problem #2: When you add another queue, you run the risk of processing events in an incorrect order.
- Say you have 2 queues: and , and events and such that happens before .
- gets sent to and gets sent to . However, the consumer checks before , so gets processed first.
-
Solution #2: The way to fix this is to make sure that all events that are causal go to the same queue. In the World Cup example, this means that all events of the same game will be sent to the same queue. You do this by introducing a partition key that will be hashed that will determine the queue that the event goes to.
-
Problem #3: If you are able to do all of these, there is also a chance that events from the producer are coming in faster than the consumer can handle. This can cause a backlog in the queue system
-
Solution #3: Introduce multiple consumers so that events can be processed in parallel. However, you do not want events to be processed more than once. You introduce consumer groups such that events can only be processed exactly once by a consumer group.
-
Topics:
- Topics are a concept that makes sure consumers only consumer and process messages that they need to care about. Consumers subscribe to topics, and producers publish their messages to the topic that it belongs to, and so only the consumers that are subscribed to the topic that was published to will be able to consume the message
-
All these solutions combined give you a high level overview of Kafka
Kafka Overview
- Terminology
- Brokers: The actual servers that hold Kafka queues
- Partitions: The queue instances themselves. Immutable, ordered sequence of messages we can only append to.
- Topics: Logical groupings of partitions
- Producers: Write/publish messages to topics
- Consumers: Take and process messages from partitions
- Under the hood:
- Producers will create messages/records to be published
- Each message has the following attributes:
- Key
- Value
- Headers
- Timestamp
- Each message has the following attributes:
- Kafka assigns these messages to the appropriate topic, partition, and broker
- First, it checks to see if a key is present (key is optional)
- If key is not present, there will be random logic, or round robin logic to determine partition
- If key is present, then we perform hash on the key to get the partition that the message will go to.
- Then identify broker for that partition that message will be sent to. Controller has a mapping of partition to broker
- Send message to broker
- Broker appends message to the partition
- Kafka appends message to the partition
- Each message is appended to the next available offset in the log file of the partition
- Consumer reads the message from partition
- Consumer reads next message by sending the offset of the latest message that it has read. That way, kafka will know which message to send next.
- Consumer could crash and restart and forget what offset it has. To fix this, consumers periodically send the offset they are on to Kafka, so Kafka stores the state of the consumers in case of a restart/crash of consumer.
- Producers will create messages/records to be published
- Durability and Availability:
- Kafka has a robust replica system that helps its durability and availability. There is one leader replica that handles reads and writes of all partitions, but there are many follower replicas that stay in sync with the leader. This is so the follower replicas are prepared to take over role as leader replica if the leader replica were to crash.

When to use Kafka
- When you need message queues:
- Async processing:
- You have a process that would take very long to be performed in a synchronous request. Example is you are uploading a video to YouTube, and the video needs to be transcoded to multiple resolutions. The transcoding process is too long to be handled in a synchronous process.
- Instead you publish a message to a Kafka queue and have a transcoder service that subscribes to the topic and consumes the message to transcode the message.
- This means the synchronous call will end after publishing the message and the video will eventually be transcoded.
- In order event processing
- Example is ticketmaster waiting queue.
- Imagine a very popular event with a large amount of people trying to book tickets for it. You can put people in a kafka queue and wait some amount of time before letting some batch of them in. This will decrease the load on your servers in the backend.
- Decoupling producers and consumers
- You use Kafka to decouple producers of messages/information from consumers/processors of messages/information so that you can scale each of them independently without worrying about the other.
- Reduce complexity
- Async processing:
- When you need event streaming:
- Event streaming is real time processing of lots of data.
- An example is ad clicking aggregator, where every time an ad is clicked, that event needs to be sent to some activity tracking service for ads
Client --> Producer --> Kafka (Ad Click Stream) --> Consumer (Flink) --> DB (store count of number of times ad clicked)- Another example is needing to send messages to multiple consumers at the same time. Like commenting on an Instagram Live. When you make the comment, it can publish the comment to some topic that all viewers of the livestream are subscribed to so that the comment gets sent to them in seemingly real time.
Deep Dives on Kafka
Scalability
- Constraints on Kafka:
- Aim for < 1 MB per message for optimal performance
- Each broker can store about 1 TB of data, and can handle ~10k msgs/sec
- Do not send full blob through the message. Just send s3 url or something similar that allows you to retrieve the data
- How to Scale:
- Add more brokers, which gives you more disk space and gives more potential throughput
- When you do this, you need to make sure that you are choosing a good partition key that will evenly distribute your data across all brokers
- Hot Key Problem:
- This happens when a single key gets accessed super often, so the partition that the key would go to gets overloaded with requests
- How to handle this?
- You can remove the key, as the key is optional. You can do this if ordering is not that important to you.
- Create a compound key by appending a random number to the end of the key to have it get sent to random partitions Fault Tolerance/Durability
- As stated before, Kafka has robust replication strategy that makes sure there are follower replicas ready to take over leader replica if leader goes down.
- Relevant Configs in Kafka for fault tolerance:
- Acks: The number of replicas that need to acknowledge the ingestion of a message before the message can be deemed to be sent successfully. High # of acks will mean higher chance of durability of message, but decreases performance. Opposite is true for low number of acks. Need to balance
- Replication factor: Number of replicas you want. Same story. Higher # ⇒ Higher durability, slower performance. Error Handling/Retries
- Producer retries:
- Similar to API retries. Just retry at a given interval until the message has been published to the partition successfully.
- Consumer Retries:
- You have a main topic, a retry topic, and a DLQ topic.
- Main topic is for the first time the message is processed. If the first attempt fails, send the message to the retry topic to be retried in case of a transient failure.
- If after a certain amount of retries the message still fails, place message on DLQ topic. No consumer for this topic. Message sits here and alerts engineer that it failed, and engineer figures out why it failed. Performance/Optimizations
- You can compress messages using some compression algorithm like GZIP to decrease the size of messages being sent and consumed. Better network and memory efficiency.
- You can batch messages in producer to increase throughput and decrease number of requests the brokers have to handle.
PostgreSQL (PSQL)
The most common database to use in system design interviews.
Motivating Example (Social Media Platform)
- In social media platform, handle the following fundamental relationships:
- Create posts
- Comment on posts
- Like posts and comments
- Direct Message
- Follow other users
- Each of these requires different requirements that PSQL can handle:
- Atomic operations for multistep functions
- Some operations can be eventually consistent.
- Comments must have referential integrity
- Users should be able to search
- PSQL good for complex relations, searching, scaling, and mixed consistency.
Core Capabilities
- Read performance
- Really good for when # of reads >> # of writes
- Able to use indexing to be able to perform fast retrieval.
- Uses B-trees for basic indexing, which is good for range and exact queries.
- Also has advanced indexing capabilities
- Inverted index that is usually used for full text search.
- JSONB columns can be used to add additional json like attributes that you can search for.
- Geospatial indexes also supported in PSQL if need to deal with geospatial data.
- Query Optimization Essentials
- Covering indexes:
- Instead of the indexes storing the location of where the data is for the DB to go retrieve it, the index stores the data itself so faster retrieval
- Partial indexes:
- Similar to covering indexes, but instead of storing all of the data at the index, only store specific partial data (select fields)
- Covering indexes:
- Performance Numbers
- Query Performance
- Simple index lookups: 10k/second per node
- Complex joins: 1k per second per node
- Scale Limits
- Stay < 100M rows
- Full text search ⇒ stay < 10M rows
- Complex joins ⇒ stay < 10M rows
- Query Performance
- Write Performance
- Several optimizations made to ensure performance and durability
- Changes first written to the Write Ahead Log (WAL) to ensure durability if the DB crashes
- Buffer Cache Update: The buffer cache, which is where the indexes and data live in memory, are updated, and the page(s) that were modified will be marked as dirty so they will be written to disk eventually. Write to buffer memory cache needed for performance.
- Memory pages asynchronously written to disk.
- Indexes are updated with the new data, and the changes to the indexes need to also be written to the WAL. Because of the overhead of updating indexes, if you have a lot of indexes, youl will degrade your write performance.
- Because the synchronous operation of writes is just a write to memory, it is a fast operation.
- Write Performance Numbers
- Simple inserts: ~5k/node/sec
- Update with index modifications: 1k-2k/node/sec
- Complex transactions: 100/node/sec
- Note: These numbers are given with the assumption of using default read commit isolation
- Write Optimizations
- Ways to optimize writes
- Vertical Scaling
- Faster disk, more storage for caches, increase cores for parallelism
- Batch Processing
- Collect multiple writes and put them all into one transaction to increase throughput
- Write Offloading
- Send writes to kafka queue to be done asynchronously
- Table Partitioning
- Split data across multiple instances when you have a lot of data.
- Also if each partition is independent, then you can have multiple writes at the same time.
- Sharding
- Distribute writes across many PSQL instances
- Several optimizations made to ensure performance and durability
- Replication
- Used to scale reads in PSQL by distributing queries across multiple replicas of DB.
- Also provides high availability.
- Synchronous replication: When replication has to happen before returning the success response to client. This emphasizes consistency, but will suffer on availability.
- Asynchronous replication: when replication happens in background, and it is not needed to return successful response to client. This emphasizes availability over strong consistency.
- This form of single-leader replication is good for heavy read apps where reads >> writes.
- High Availability
- With multiple replicas, if one replica goes down, other replicas can handle read requests as well.
- If the primary node goes down, a replica has to replace the primary node:
- DB Admin detects failure
- Replica promoted to primary
- Update connection info so writes go to new primary
- Reopen application
- Data Consistency
-
Postgres good if you want consistency over availability because provides ACID guarantees with transactions
-
Transactions
- Set of operations executed by DB that either all fail or all succeed. No in between.
- PSQL ensures consistency for single series of operations
- When multiple transactions are happening at the same time, it gets more complicated trying to preserve the ACID guarantees.
- We can add the following:
- Row level locking: Lock rows such that when a transaction acquires the lock for a row, it is the only operation that can modify or access that row.
- Add stricted isolation levels (e.g. Serializable isolation)
- Serializability v.s. Row Locking
- Serializability will have a lot more overhead, especially when there are multiple shards/partitions
- Less scalable as well, but it is more simple to implement.
-
When to use PSQL and When Not to
- Postgres is the default DB choice to use in System Design interviews:
- Provides ACID guarantees
- Handles both structured and unstructured data
- Offers advanced indexing capabilities
- Offers replication
- Good for:
- Data with complex relations
- Strong consistency guarantees
- Rich query capabilities
- Examples (eCommerce, Financial Systems, Booking Systems, Social Media)
- When to consider alternatives
- You need an extreme amount of write throughput
- Might need to use NoSQL DB like Cassandra or DDB
- Multi-region Requirements
- PSQL does not natively support partitioning
- Uses single leader replication, so cannot handle distributed transactions well
- Use CockroachDB for global ACID guarantees.
- If you want eventual consistency at global scale, use Cassandra
- Simple Key Value Access Pattern
- If you are just doing key-value access patterns, might be overkill to use PSQL. Just use redis instance.
- You need an extreme amount of write throughput
ACID with Transactions
- (A)tomicity
- All operations in Transaction will all succeed or all fail
- (C)onsistency
- DB goes from a previous valid state to another valid state after a transaction
- (I)solation
- PSQL has different levels of isolation it can achieve based on configuration
- (D)urability
- Changes all written to WAL first, for durability.
Zookeeper
Zookeeper is an orchestrator services used to coordinate operations in distributed systems.
Motivating example: Chat App
-
If you have multiple servers, you would need to somehow be able to connect users who may be on different servers together. How do you make this happen?
-
You can store the server each user is on in a DB, but if DB goes down, then your whole app goes down (single point of failure)
-
Also what happens when one server goes down, etc. etc.
-
Zookeeper intends to provide a consistent, reliable source of truth that all servers in a system can trust. (e.g. maintaining a map of users to what server they reside on)
Zookeeper Basics
Data Model: ZNodes
- Zookeeper organizes data similar to how a file system organizes data. (e.g. hierarchical with directories)
- Each node of data is a Znode that stores < 1 MB of data + metadata (lots of nodes, little data in each)
- Three types of ZNodes
- Persistent ZNodes: Exist until explicitly deleted. Used to store global config data that is always needed
- Ephemeral Nodes: Created to store session scoped data (e.g. who is online, what server they exist on). They get automatically deleted when the session is deleted.
- Sequential ZNodes: automatically appended with monotonically increasing counter. Like an append log. Used for ordering or distributed lock
- Chat app would use a structure similar to this
/chat-app
/servers # Directory of available servers
/server1 # Ephemeral node containing "192.168.1.101:8080" the location of this server
/server2 # Ephemeral node containing "192.168.1.102:8080" the location of this server
/server3 # Ephemeral node containing "192.168.1.103:8080" the location of this server
/users # Directory of online users
/alice # Ephemeral node containing "server1" the server that alice is connected to
/bob # Ephemeral node containing "server2" the server that bob is connected to
/config # Application configuration
/max_users # Persistent node containing "10000" the maximum number of users allowed
/message_rate # Persistent node containing "100/sec" the maximum number of messages per second allowed
- This allows for us to store which server each user sits in by looking up each user node.
Server Roles and Ensemble
- ZK runs on ensemble of servers to prevent single point of failure.
- Server Roles:
- Leader: Handles all writes and all updates. Leader is elected
- Follower: Serves as read replica
- If follower fails, no big deal. If leader fails, then election process happens then re-election needs to happen
Watches: Knowing when Things Change
- Notification mechanism built into ZK.
- Allow servers to be notified when some ZNode changes, eliminating Polling or other communication needs.
- In a chat app, it helps servers know when users may connect to a different server, so the messages can still be routed properly.
- Help servers keep local cache of ZK state.
Key Capabilities
Config Management
- Keep dynamic configurations similar to AWS AppConfig and feature flags.
Service Discovery
- Service discovery is auto detecting endpoints and services. Mainly multiple endpoints of same service
- When a service comes online, they can register themselves to ZK to become available to serve traffic. When they go down, they deregister.
- Enables load balancing, health checking
Leader Election
- If you have a system operating as an ensemble, you can have each node be a sequential node in ZK, and when a node goes, down, you choose the next lowest number in the sequential ZNode to become next leader. If that one fails, keep repeating down the list.
Distributed Locks
- Coordinate access to shared resources using sequential ZNodes.
- Each client accessing the resources creates a sequential ZNode. The client with lowest number on the lock acquires the lock. When done with resource, delete the entry, and next client up has the lock.
- Not good for if you have high frequency locks, but good for strongly consistent locks if you really needthis.
How Zookeeper Works
- How does ZK solve its own coordination problem? Zookeeper Atomic Broadcast (ZAB)
- 2 Phases to this
- Leader election: There needs to be a leader node in ZK cluster, and this election is based on which node has most up to date transaction history
- Atomic Broadcast means that writes to leader node aren’t successful until they have been written to a quorum of the followers (usually n//2)
- Because writes require this overhead to be considered successful, Zookeeper is best used for read heavy use cases. This is why highly frequent lock acquiring was not a good use case for ZK.
- ZAB guarantees the following
- Sequential Consistency: updates from clients are persisted in order they are sent (serializable ?)
- Atomicity: Updates either completely fail or completely succeed
- Single System Image: All replicas always show same state as leader
- Durability: Updates persisted and never lost/
- Timeliness: View of system updated within a bounded amount of time.
Session and Connection Management
- Sessions are used to manage connections
- Sessions are established when they connect to ZK.
- Clients send heartbeat to ZK periodically to signal they are alive, and session stays alive.
- Session can be recovered if they disconnect from one server and connect to another one quick enough.
- Once sessions expire, all ephermal nodes related to that server are deleted, and all watches for it are removed.
Storage Architectures
- Stores everything in Transaction Log first (similar to WAL), so no transaction is lost.
- Periodic snapshots of state of ZK are kept to allow for speedy recovery.
Handling Failures
- If followers, fail, continue as normal, if leader fails, need to elect a new leader.
- If there are not enough in the quoroum, writes will fail.
- If client to ZK fails, all ephemeral nodes related to it will be deleted when session expires (Did not receive heartbeat)
Zookeeper in the Modern World
Current uses in Distributed Systems
- Not realy used in most places except in Apache ecosystems (e.g. Hadoop, HBase, etc)
- People are transitioning away from it. Example: Kafka moved to Kafka Raft Metadata (Kraft)
Alternatives
- etcd: Ideal for config management and service discovery. Also is Cloud Native.
- Consul: Good for network infrastructure automation with service discovery and health checking and configuring load balancing dynamically.
- AWS AppConfig
Limitations
- Hotspotting Issues: Many clients will be watching the same ZNode, and popular nodes become bottleneck.
- Performance Limitations: Because of its Strong Consistency guarantees, it has performance issues (slow + less available)
- Operational Complexity, an you now need to manage the ZK Cluster.
When to Use Zookeeper
- Smart Routing
- Minimizing cross server communication.
- E.g. in chat app, map chat room to server, and have people that are in the same chat room to be in the same server, so there is less cross server communication. Do this in API gateway.
- Infrastructure Design Problems
- If you are designing a distributed message queue or task scheduler in your interview, ZK is good for acting as the central brain for handling consensus and coordinating things.
- e.g. When a new broker comes up, registers with ZK.
- Electing leaders, managing subscriptions to topics.
- If you are designing a distributed message queue or task scheduler in your interview, ZK is good for acting as the central brain for handling consensus and coordinating things.
- Durable Distributed Locks
- Good for nested lock acquisition without deadlocking with the watch mechanism.
Flink
Flink is a tool that helps with real time stream processing
Example of this is ingesting clicks of an ad that popped up on an app.
Why is stream processing complex?
- It may require state, if you are looking for all events in the past 5 minutes
- How can do you recover state after a crash
- How to distribute state to a new instance if we scale up
- What happens if events come in out of order
Basic Concepts
- Flink is dataflow engine based around idea of dataflow graphs
- Dataflow graphs
- directed graphs describing the computation process on data.
- nodes are the operations, and edges are the data streams
- There is always a source node where the data comes from (e.g. queue), and a sink node where data ends up (e.g. DB)
- Streams
- Unbounded sequences of data elements flowing through a system
- i.e. an infinite array of elements
- Example:
// Example event in a stream { "user_id": "123", "action": "click", "timestamp": "2024-01-01T00:00:00.000Z", "page": "/products/xyz" }
Operators
- A (potentially) stateful operation that is performed on one or more input streams and produces an output stream
- Building blocks of stream processors
- Different operators:
- Map: transform each element
- Filter: filter out elements
- reduce: Combine elements
- Aggregate: e.g. average over a window.
- Think of java stream code.
State
- Operators in Flink maintain an internal state across multiple events (e.g. to calculate a moving average over 5 mins)
- State is managed internally by Flink to provide scaling guarantees and durability.
- Types of state:
- Value state: single value per key
- List state: list of values per key
- Map state: Map of values per key
- Aggregation State: state for incremental aggregations
- Reducing state: incremental reductions
- Example code for state:
public class ClickCounter extends KeyedProcessFunction<String, ClickEvent, ClickCount> {
private ValueState<Long> countState;
@Override
public void open(Configuration config) {
ValueStateDescriptor<Long> descriptor =
new ValueStateDescriptor<>("count", Long.class);
countState = getRuntimeContext().getState(descriptor);
}
@Override
public void processElement(ClickEvent event, Context ctx, Collector<ClickCount> out)
throws Exception {
Long count = countState.value();
if (count == null) {
count = 0L;
}
count++;
countState.update(count);
out.collect(new ClickCount(event.getUserId(), count));
}
}Watermarks
- How Flink handles out of order events. Events come out of order because of network delays, source system delays, etc.
- Events all come with a timestamp that flows through the stream processor along with the data.
- Once this timestamp flows through system, it basically declares that all events before that specific timestamp have arrived.
- E.g. An event with time stamp 5:00:00 pm comes in at 5:01:15pm. This means that all events from 4:59:59 pm have been declared to have already arrived.
- This allows for:
- Making decisions on when to compute window computations
- Handle late events gracefully
- Maintain consistent event time processing
- Must be configured on source node of stream.
Windows
- A way to group elements in stream by time or count
- Essential for aggregating data
- Types of windows:
- Tumbling windows: fixed size, nonoverlapping
- Sliding: Fixed size, overlapping
- Session: Dynamic in size (depends on session length), nonoverlapping
- Global: Customized window logic
- Once window ends, data about the window is emitted.
Basic Use of Flink
Defining a Job
- You define your source, your transformations, and your sink
Submitting a Job
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define source (e.g., Kafka)
DataStream<ClickEvent> clicks = env
.addSource(new FlinkKafkaConsumer<>("clicks", new ClickEventSchema(), properties));
// Define transformations
DataStream<WindowedClicks> windowedClicks = clicks
.keyBy(event -> event.getUserId())
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.aggregate(new ClickAggregator());
// Define sink (e.g., Elasticsearch)
windowedClicks
.addSink(new ElasticsearchSink.Builder<>(elasticsearchConfig).build());
// Execute
env.execute("Click Processing Job");- You submit a job on the Flink cluster to execute.
- Call
executemethod onStreamExecutionEnvironmantthis will:- Generate the JobGraph with Flink Compiler to create execution plan
- Submit job to JobManager that coordinates job executions
- Distribute Task to Task Manager
- Execute
Sample Jobs
- Basic Dashboarding Using Redis
DataStream<ClickEvent> clickstream = env .addSource(new FlinkKafkaConsumer<>("clicks", new JSONDeserializationSchema<>(ClickEvent.class), kafkaProps)); // Calculate metrics with 1-minute windows DataStream<PageViewCount> pageViews = clickstream .keyBy(click -> click.getPageId()) .window(TumblingProcessingTimeWindows.of(Time.minutes(1))) .aggregate(new CountAggregator()); // Write to Redis for dashboard consumption pageViews.addSink(new RedisSink<>(redisConfig, new PageViewCountMapper()));- Taking clicks of an add from a kafka queue adding to tumbling window and storing count aggregator for each window to a Redis instance to create dashboard
- Fraud Detection System
DataStream<Transaction> transactions = env .addSource(new FlinkKafkaConsumer<>("transactions", new KafkaAvroDeserializationSchema<>(Transaction.class), kafkaProps)) .assignTimestampsAndWatermarks( WatermarkStrategy.<Transaction>forBoundedOutOfOrderness(Duration.ofSeconds(10)) .withTimestampAssigner((event, timestamp) -> event.getTimestamp()) ); // Enrich transactions with account information DataStream<EnrichedTransaction> enrichedTransactions = transactions.keyBy(t -> t.getAccountId()) .connect(accountInfoStream.keyBy(a -> a.getAccountId())) .process(new AccountEnrichmentFunction()); // Calculate velocity metrics (multiple transactions in short time) DataStream<VelocityAlert> velocityAlerts = enrichedTransactions .keyBy(t -> t.getAccountId()) .window(SlidingEventTimeWindows.of(Time.minutes(30), Time.minutes(5))) .process(new VelocityDetector(3, 1000.0)); // Alert on 3+ transactions over $1000 in 30 min // Pattern detection with CEP for suspicious sequences Pattern<EnrichedTransaction, ?> fraudPattern = Pattern.<EnrichedTransaction>begin("small-tx") .where(tx -> tx.getAmount() < 10.0) .next("large-tx") .where(tx -> tx.getAmount() > 1000.0) .within(Time.minutes(5)); DataStream<PatternAlert> patternAlerts = CEP.pattern( enrichedTransactions.keyBy(t -> t.getCardId()), fraudPattern) .select(new PatternAlertSelector()); // Union all alerts and deduplicate DataStream<Alert> allAlerts = velocityAlerts.union(patternAlerts) .keyBy(Alert::getAlertId) .window(TumblingEventTimeWindows.of(Time.minutes(5))) .aggregate(new AlertDeduplicator()); // Output to Kafka and Elasticsearch allAlerts.addSink(new FlinkKafkaProducer<>("alerts", new AlertSerializer(), kafkaProps)); allAlerts.addSink(ElasticsearchSink.builder(elasticsearchConfig).build());- Looking for specific patterns of clicks related to fraud (e.g. velocity of transactions, specific sequences)
- Querying using sliding windows, checking individual components of the data, and triggering alarm if a fraudulent pattern is found.
How Flink Works
- Two main types of processes in a flink cluster:
- Job manager: coordinator of jobs (e.g. scheduling, coodinating checkpoints, handling failures)
- Task Manager: Actual workers executing the data processing.
- Job managers are leader based (i.e. there is one leader job manager with quorum based mechanism)
- Use ZK for electing leader
- When submitting job:
- Job manager receives application and constructs execution graph
- Allocates tasks to slots in task managers
- TM executte teasks
- JM monitor tasks and handle failures.
Task Slots and Parallelism
- Each TM has task slots, which are basic unit of scheduling. (e.g. # of cores on machine)
- Slots reserve capacity and resources on machine to execute tasks.
- Isolate memory b/w tasks, control number of parallel task instances, and enable resource sharing between different task on same job.
State Management
- How does Flink manage state and recover from system crashes/failures gracefully?
- State Backends
- There is a backend that basically manages storage and retrieval of state.
- Similar to a DB that stores state
- Different types:
- Memory backend: Store on JVM heap. Allow for faster access
- Filesystem Backend: Store in filesystem
- RocksDB Backend: store in a RocksDB instance
- Mainly, people use memory backend because it is most performant, but if you have very large state, you may want to consider other options.
- Can also try storing state in a storage service provided by cloud provider (e.g. S3)
- Checkpointing + Exactly-Once Processing
- Checkpointing to recover state
- Uses Chandrey-Lamport Algorithm for distributed snapshotting to take snapshots of state.
- Job manager initiates checkpoint by sending a “checkpoint barrier” event to sources.
- When operator receives barrier event from all inputs, it takes snapshot of state by serializing and storing in backend.
- When all done, checkpoint is registered with Job Manager
- We can restore state with this
- When failure occurs:
- Job manager detects failed job
- Job is paused by JM. All tasks stopped
- State is recovered from most recent checkpoint in backend
- Tasks are redistributed from failed Task Manager to all healthy Task Managers.
- Tasks restore state
- Sources rewind to checkpoint positions
- Resume processing
- Flink guarantees exactly once processing of events.
In Interview
- Some things to know
- Flink is usually overkill. You could probably set up a service that transforms messages from Kafka and sends to DB.
- Flink ⇒ significant operational overhead.
- State management biggest operational challenge
- Window choice dramatically can change performance of Flink
- Do you really need Flink?
- For the most part, not recommended to use Flink in most systems
Lessons From Flink
- Borrowing several principles from Flink
- Separation of time domains: Event times are different from processing time
- Watermarks for progress tracking: Watermark useful concept for tracking progress through unordered events
- State management patterns: Good practices for handling state durably
- Resource Isolation: Slot based management
Cassandra
- Cassandra is a NoSQL database that is good if you have large amounts of data, only need eventual consistency, and you need a high amount of write throughput.
Cassandra Basics
Data Model
- Keyspace:
- Data containers likened to databases. Contain many tables
- Own configuration information about tables like user defined types
- Table:
- Container for data in form of rows
- Column:
- Contains data belonging to rows.
- Columns can vary by row, meaning column of one row may not be in another row.
- Makes data schema able to be flexible
Primary Key
- Consists of partition key and clustering key:
- Clustering Key: Zero or more columns used to determine sorted order of rows
- Partition Key: One or more columns used to determine the partition the row resides in.
- Is unique
Key Concepts
Partitioning
- Achieve horizontal scalability by partitioning data across nodes with consistent hashing.
- How to handle hot node problem?
- Cassandra has concept of virtual nodes and physical nodes.
- multiple vnodes can be mapped to one physical node
- Distributes load evenly across nodes
Replication
- Data can be replicated to other nodes to increase availability
- Done by going clockwise along the consistent hash ring
- Must replicate to vnode that does not exist on same physical node as origin
Consistency
- Does not support ACID guarantees, but supports BASE
- Only has atomic and isolated writes
- Uses quorum to determine how many nodes are required for a success.
Query Routing
- Every node in Cassandra cluster can take requests, because all nodes can act as a coordinator node to direct request to the node it needs to go to.
- All nodes know about each other statuses and can tell if they’re alive with “gossiping”
Storage Model
- Uses Log Structured Merge for writes, which is basically append only log for all updates made to the DB to increase speed.
- This increases write throughput greatly.
- 3 core constructs of LSM:
- Commit log - write ahead log for durability
- Memtable - Map living in memory that maps each row to their location on disk.
- SSTable - Sorted String Table that is flushed previous memtables
- What does a write look like:
- Write issued
- Written to commit log
- Written to memtable
- Once memtable full, memtable flushed to disk as SSTable
- Commit logs related to flushed memtable deleted because now data is durable.
- When Reading
- First read memtable to find the data by primary key.
- If not in memtable, then use Bloom filter to see if it is in an SSTable. If it is, scan SSTables.
- Compaction:
- merging of SSTables to get rid of deleted data and duplicate data to clean up storage
- SSTable indexing - Store files pointing to byte offset of SSTables to enable faster retrieval of data on disk. (E.g. Store key 12 to byte offset 984 to say data for key 12 is find at byte offset 984 on disk)
Gossip
- How Cassandra nodes communicate.
- Every node is able to perform all operations, allowing for peer-to-peer scheme for distributing information across nodes. Universal knowledge.
- Nodes use generation and version numbers for each node they know about to track various information about all nodes.
- Generation - timestamp for when node was bootstrapped
- Version - logical clock value incrementing every second. Across cluster, this creates vector clock
- Nodes gossip with other nodes to determine if they are alive
Fault Tolerance
- Uses Phi Accrual Failure Detector technique to detect failures during gossip
- Each node makes independent decision on if node they are gossiping with is dead or alive
- If node gossips with another node, and it does not respond, it will determine it as down.
- When node is alive again, it can reenter cluster.
- Use Hinted Handoffs
- If a node is down, and a write is supposed to go to it, coordinator will write it to another node for write to succeed, and when offline node comes online, hints get sent to the previously offline node.
- Not a good long term solution. Only works for short term offlines
How to Use Cassandra
Data Modeling
- Have to take advantage of NoSQL structure of Cassandra by denormalizing data to be able to access data faster.
- Cassandra not good at joins, so you should denormalize data across tables to make queries faster
- Consider what should be:
- Partition Key: What data should determine partition
- Partition size: How big should partition be
- Clustering Key: What needs to be sorted
- Denormalization: What data should be denormalized
- Discord Messages
- Discord channels are busy with messages
- Messages should be sorted by timestamp from most recent to least recent
- Use monotonically increasing timestamp to prevent conflicts. This is
message_id. Keeps each key unique.
- Use monotonically increasing timestamp to prevent conflicts. This is
- Messages from the same channel should live in the same partition, so your partition key should be
channel_id. Also addmessage_idas clustering - However, this would cause hotspot issues again for popular channels
- Use bucket concept, where every ten days worth of data of a channel gets a new bucket id and this
bucket_idbecomes the new partition key. - Key takeaway: _Because most queries are for most recent messages, wouldn’t mostly have to query for more than one bucket
- Relative schema
CREATE TABLE messages ( channel_id bigint, bucket int, message_id bigint, author_id bigint, content text, PRIMARY KEY ((channel_id, bucket), message_id) ) WITH CLUSTERING ORDER BY (message_id DESC);- It is clear that the way the data is queried for is driving the design
- Ticketmaster
- Ticket browsing UI.
- The UI doesn’t need to have strong consistency because it is updating all the time.
- Once purchase flow is triggered, than consistency is needed.
- Each seat is a ticket. Tickets for the same event should be in the same partition, so
event_idshould be partition key. Also addseat_idas clustering key to guarantee uniqueness. - Because each event can have > 10K Seats, this may not be enough of a partition key. You can add
section_idas part of partition key which represents what section of the stadium seat is in.
CREATE TABLE tickets ( event_id bigint, section_id bigint, seat_id bigint, price bigint, PRIMARY KEY ((event_id, section_id), seat_id) );- If we want to be able to query for high level stats, we can create a new table only with partition key being
event_idto make high level queries.- This is example of denormalizing.
Advanced Features
- Storage Attached Indexes (SAI)
- Offer global secondary indexes like DDB.
- Offer more flexible querying of data and avoid excess denormalizing of data.
- Materialized Views
- Create new tables of aggregated metrics and stuff. Or materialize a denormalized table based on a source table
- Don’t need to keep track of denormalized data in application layer.
- Search Indexing
- Can be wired up to ElasticSearch
Cassandra in Interview
When to Use it
- When you are prioritizing availability over consistency, and you need high write throughput.
- Also good when you have clear access patterns
Knowing its Limitations
- Not good if you need strict consistency, or if you have complex query patterns that would require many joins and stuff
- If you need strict consistency, better off with PostgreSQL or MySQL.
Common Patterns
Real Time Updates
The Problem
You want to be able to send real time updates from the server to the client. E.g. Google Docs — getting updates for the document you are collaborating on.
The Solution
- There are two phases to developing real time updates for clients:
- How do we get updates from the server to the client
- How do we get updates from the source of events to the server.
Phase 1
Client Server Connection Protocols
- How to establish efficient communication channels between client and server such that servers can push updates to client.
- Networking 101
- See above for basics in networking
- Main topic is layers of networking
- Layer 3 - Networking Layer. Where IP lives. Routing packets from one IP to another.
- Layer 4 - Transport Layer. TCP vs UDP. End to End Communication Service
- Layer 7 - Application layer. HTTP/WebSocket
- Request Lifecylce
- Main takeaway is that there are a lot of steps for a basic request, which adds a lot of latency, which is not good for real time updates.
- Also, TCP connection represents state, which is not easy to maintain.
- Simple Polling: The Baseline
- The simplest approach to real time updates is for client to regularly poll server for updates
- Very basic, but can often be all that is needed, because most applications don’t actually need super real time updates.
async function poll() { const response = await fetch('/api/updates'); const data = await response.json(); processData(data); } // Poll every 2 seconds setInterval(poll, 2000);- Advantages:
- Simple to implement, stateless, no special infra
- Disadvantages:
- Higher latency than other advanced solutions, more bandwidth usage, and more resource usage in general.
- When to use:
- Only when you don’t actually need real time and low latency
- Long Polling: Easy Solution
- Clever hack on simple polling
- Server holds request open until data polled for is available (or timeout)
- Cuts number of requests down.
- Not good if you have high frequency of events
// Client-side of long polling async function longPoll() { while (true) { try { const response = await fetch('/api/updates'); const data = await response.json(); // Handle data processData(data); } catch (error) { // Handle error console.error(error); // Add small delay before retrying on error await new Promise(resolve => setTimeout(resolve, 1000)); } } }- Because of client callbacks, you can introduce some extra latency.
- For example, you poll and wait, and get event 1 and event 2 comes right after. You process event 1, and have a delay before requesting again, you wait more time for event 2 than you want to.
- For example, you poll and wait, and get event 1 and event 2 comes right after. You process event 1, and have a delay before requesting again, you wait more time for event 2 than you want to.
- Good only if you have infrequent events and a simple solution is preferred
- Server Side Events (SSE)
- Client sets up a call to server with a callback to perform an action when event is received
- A long connection is kept to support a “stream” of data coming from server to client
- How it works:
- Client establish connection
- Server keeps it open
- Server sends messages when updates happen
- Client receives update.
- Good for a chat app, each message will be sent as a chunk to the client
- It works out of the box for most browsers and is good for high frequency updates, more efficient than polling, and simple to implement
- It only allows for server to client communication
- It is good to use when
- High frequency updates, AI Chat apps (streaming new tokens to user)
- Uses HTTP infrastructure.
- Each connection is usually 30-60 seconds, so if you need connection open for longer time, you need client to be able to re-establish connection.
- Use last event ID so client can tell server last event it received, and EventSource object in browser handles re-establishing of the connection.
- WebSockets:
- Go to choice for bi-directional communication
- Hold two way connection open for very long time between client and server.
- Client and server can send bytes of data both ways (blobs of data)
- Because it is persistenct connection, need infrastructure support
- Usually need L4 load balancer in the middle
- How can we re-establish connections during deployments
- It is a stateful connection.
- It is only good for bidirectional communication. It is not good if you have a high number of clients.
- Powerful tool, but adds a lot of complexity need to be ready to discuss.
- WebRTC
- Good for Peer to Peer connection.
- Based on UDP protocol, so good for Video conferencing systems
- Very complex, requires a lot of infra and set up.
- Good for when you need really low latency (e.g. video conferencing, online games)
Client update Flowchart:
Phase 2
- This is how to get events to server from the source of the events.
- Pulling via Polling
- Similar to Server to Client, the server can poll the DB, or whatever the source of the event is, and mark an update when receive data.
- Same pros and cons as server to client polling
- State is constrained to DB for updates.,
- High latency.
- Not good if you really want real time updates.
- Pushing via Consistent Hashing
- Users are assigned to server deterministically using consistent hashing, and you can use Zookeeper to store this mapping.
- Then when update source needs to send update to user, it will query Zookeeper for the server the user lives on, and send the update to that server so that the client can get the update.
- You use consistent hashing for assigning users to servers to minimize the number of users that need to migrate from one server to another when one node is removed or added.
- When adding or removing node, you need to have a transition period where the old server the user lived on and the new server they live on both receive updates just in case.
- Good for when you need long persistent connections (e.g. WebSocket) and your system needs to scale dynamically.
- Pushing via Pub Sub
- Single service that is responsible for collecting updates from a source and sending them to the interested clients. (e.g. Redis PubSub, AWS SNS/SQS, Kafka)
- Servers will register clients to pub/sub server so that updates can be sent to them. No need to assign users to specific servers.
- Good if you have a large amount of clients and minimal latency.
- It becomes a single point of failure in our system. If Pub/Sub service goes down, no more updates. You can perform replication and sharding and cluster of services to add redundancy.
When to Use in Interviews
- Appear in a lot of interview problems with user interaction or live data.
Common Scenarios
- Chat applications
- messages must appear in real time across all participants. Good to use SSE or websocket for phase 1 and pub/sub for phase 2.
- Live Comments
- Real time social interaction during live events. Millions of people commenting on an Instagram Live. Need to use Hierarchical aggregation/batching
- Google Docs
- WebSockets + CRDTs
- Live Dashboards
- Operational data constantly changing. Use SSE.
- If you can get away with simple polling, use it!
Common Deep Dives
How to handle connection failures and reconnection?
- Detecting disconnections quickly and reusming with 0 data loss.
- Implement heartbeat mechanism to detect “Zombie” connections
- Need to be able to track what messages a client has received, so when reconnects, server can send all events client has missed.
- Per user message queue, or sequence number for events What happens when single user has millions of followers that need same update?
- Comment posted on celebrity instagram live. Need multiple layers to add hierarchical distribution. Users write to different write processors that process the write, get sent to root processor, and then gets sent to different broadcast nodes that will take a batch of users to send the notification to.
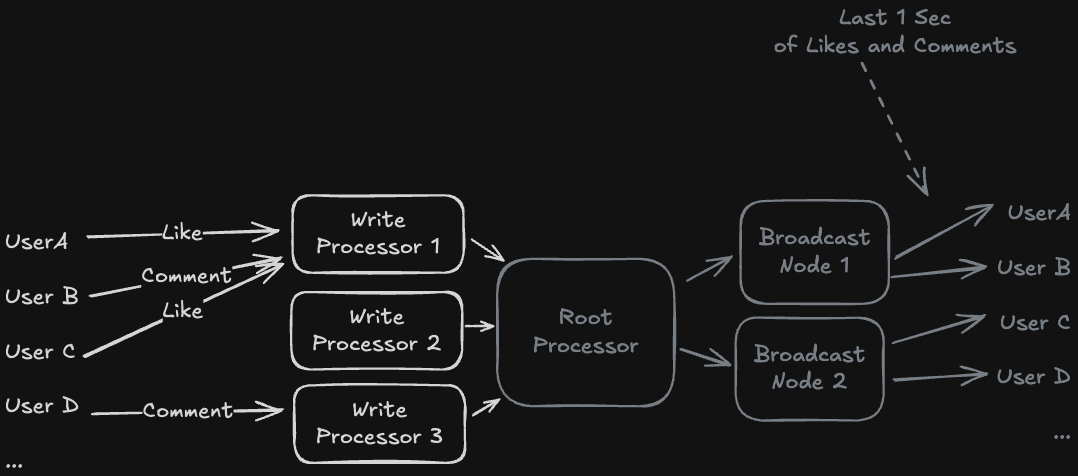 How to maintain message ordering across multiple servers?
How to maintain message ordering across multiple servers? - Vector clocks or logical timestamps help establish ordering relationships between messages.
- Each server maintain a clock, and each message gets an associated timestamp to determine correct order.
Dealing With Contention
- Contention happens when multple processes try to compete for the same resource(s)
- E.g. Booking the last ticket for an event, bidding on an auction item.
Problem
- Consider following situation buying the last ticket of an event
- Alice sees 1 seat available
- Bob sees 1 seat available
- Alice proceeds to payment
- Bob proceeeds to payment
- Alice charged, seat count goes to 0.
- Bob also charged, seat count goes to -1.
- Seat is double booked
- Example problems this shows up in
- Ticketmaster
- Online Auction
- Rate limiter
The Solution
Single Node Solutions
-
If all data exists in single DB node, more straightforward solution
-
Atomicity
- Means a group of operations either all fails or all succeeds. No partial completion.
- Using a DB that supports atomicity using transactions usually can solve most contention problems
- For concert ticket situation, atomicity ensures that all related operations happen together
BEGIN TRANSACTION; -- Check and reserve the seat UPDATE concerts SET available_seats = available_seats - 1 WHERE concert_id = 'weeknd_tour' -- Create the ticket record INSERT INTO tickets (user_id, concert_id, seat_number, purchase_time) VALUES ('user123', 'weeknd_tour', 'A15', NOW()); COMMIT;- However, still, a seat can be double booked, because transactions provide atomicity within themselves, and does not prevent other transactions from reading the same data concurrently. Would need serializability for that.
- Need coordination mechanism for this
-
Pessimistic Locking
- Prevent conflicts by acquiring locks upfront for row of data so only one transaction at a time can access it.
- Pessimistic because we are assuming conflicts will happen, and we are preventing them.
- This can decrease performance because less concurrency in the system
-
Isolation Levels
- This will control how much concurrent transactions can see each other’s changes
- 4 Levels
- Read Uncommitted: All transactions can see each others uncommitted changes. Least isolated
- Read committed: Transactions can only see changes that have been committed.
- Repeatable Read: Same data read multiple times within a transaction stay consistent. Basically taking a snapshot before the transaction
- Serializable: Transactions appear as though they are happening sequentially
- 4 is the only one that will prevent double booking, but it heavily decreases performance
-
Optimistic Concurrency Control
- This is optimistic because we are assuming conflicts won’t happen, so we will only resolve them when they happen
- This increases performance and decreases the overhead.
- You can just include a version number with all data, and everytime you update data you increment the version
- When updating data, you specify the expected current version and the new version.
- With 2 contending transactions, 1 will fail because the other one will have incremented the version number
- OCC only makes sense when contention will probably be rare. (i.e. not good for ticketing system)
Multiple Nodes
- Handling concurrency with multiple nodes for DB is different from single node approaches.
- Example
- When you have Bank Account A and B, and you want to transfer money from A to B, but A and B live on different DB nodes, the operation must be atomic across multiple nodes.
- 2 Phase Commit
- Have a server act as coordinator managing the transaction and committing all changes if all changes succeed or rolling them back if one fails.
- Coordinator writes to persistent log before committing/aborting for recovery purposes
- Phase 1: Prepare
- All changes are done in all DB nodes except for final commit
- Phase 2: Commit
- If all changes prepared successfully, commit all changes
- If any failed, rollback everything.
- Should also include timeouts in case coordinator crashes
- Distributed Locks
- Simpler mechanism with less overhead.
- Acquire a lock on some resource before performing the operation (e.g. for bank transfer, use account IDs)
- Using Redis w/ TTL
- Redis already has atomic operations (SET)
- Use SET to acquire a lock, and let the TTL handle the release and clean up of the lock when done
- All servers access the same redis instance.
- One con is Redis becomes single point of failure
- DB Columns
- Add status + expiration columns on tables to track which resources are locked.
- Leverage ACID properties of DB to acquire locks, and use background processes to clean up locks periodically.
- More complex, but no additional infra
- Zookeeper
- Use a dedicated coordintator service for strongly consistent locks
- Most robust, but most overhead.
- DL’s prevent contention before it happens.
- Saga Pattern
- Break all operations into sequency of independent steps that can be undone if something goes wrong.
- Each step has a compensation step that can reverse the step if step after fails.
- Like making every step into a transaction that can be rolled back.
- Creates an eventually consistent system, but makes it more practical to manage than 2PC.
Choosing the Right Approach
- Single DB, High Contention ⇒ Pessimistic locking
- Single DB, low contention ⇒ OCC
- Multiple DB, must be atomic ⇒ 2PC
- Multiple DB, user experience is important ⇒ Distributed Locking
When to Use in Interviews
- Multiple users trying to access same limited resources
- Prevent double booking/double charging
- Handling Race Conditions
- Ensure data consistency.
Common Interview Scenarios
- Online Auction System - Optimistic concurrency control to be used because multiple bidders compete for same item, and you can use the current high price as the “version”
- Ticketmaster - Will have high contention, would want to use some application level coordination to allow reserve booking for 10 min duration (i.e. acquiring a lock for 10 mins)
- Banking - Need it to be atomic, need to use 2PC for distributed DB or pessimistic locking or serializability.
- Ride Sharing Dispath (Uber): App level coordination using driver status.
- Inventory System: OCC
When not to Overcomplicate it
- When you have low contention scenarios with rare conflicts
- When you have single use operations
- Read heavy workloads ⇒ rare write conflicts
Common Deep Dives
How do you prevent Deadlocks with Pessmistic Locking?
- Use ordered locking which means locks must be acquired in the same order no matter what to prevent deadlock scenario
- Add database timeout configs as a safety net in case dead lock happens
What happens when coordinator service crashes during distributed transaction?
- Use a persistent lock to be able to start up a new coordinator service and recover back to its current state and completes in flight transactions
How to handle ABA problem?
- If you have a record that changes its value from A to B then back to A between a read and write, optimistic control won’t detect this.
- You have to make sure you use a column that always is changing and probably is monotonic so it is impossible for the same value to be read again. (e.g. number of reviews.)
What about performance when everyone wants the same resource
- The celebrity/hot partition problem
- Demand concentrates on a single point
- You first try changing the problem by trying to loosen the constraints
- E.g. for all demand coming to one auction item, have 10 separate identical items with separate auction on each.
- Loosen consistency constraints that you need if you really don’t need them
- Add a message queue between worker and server to absorb the pressure and create queue-based serialization
- This will lead to increased latency and decreased throughput.
Data Modeling
- Data modeling is defining how your data is structured, stored, and accessed.
- It will be a part of defining your core entities and high level design
- Database Model Options
- Relational DB (MySQL, PostgreSQL)
- data stored in rows in tables
- each table is a core entity, and you use foreign keys to perform joins
- Document DB (MongoDB)
- Data stored in JSON like objects
- Data is denormalized to perform complex queries
- Flexible data schema
- Key value store (DDB, Redis)
- Usually used for caching
- Fast but limited lookups
- Wide Column Stores (Cassandra)
- Column families
- Support high throughput on writes
- GraphDB
- data stored in nodes and edges of a graph.
- Relational DB (MySQL, PostgreSQL)
Schema Design
- 3 Key factors when deciding the schema
- Data volume — how much are you going to have to store
- Access Patterns — What would you usually query by, and would you read a lot more than you write?
- Consistency Requirments — Do you need strong conssitency or can you live with eventual consistency.
** Entities, Keys, Relationships**
- Primary Key ⇒ Unique identifier for each record in table
- Foerign Key ⇒ references to primary keys in other tables to represent relationships between entities
- Example: Instagram
- Users Table
- user_id (pk), email, …
- Posts Table
- post_id (pk), user_id (fk), content
- Comments Table
- comment_id (pk), user_id (fk), post_id (fk)
- Users Table
Normalization vs Denormalization
- Normalization means that data is stored in exactly one place in a Database
- This prevents inconsistent data, as when you update data, you don’t have to keep track of all the places that you store the data to update it.
- Denormalization means to deliberately duplicate data in multiple places to simplify queries, and increase performance on accessing data
- You should want to start with data normalized, and denormalized when you need to
Indexing
- Creating data structures in a DB on specific attributes to increase performance of querying by that attributed
- You want to index on attributes that would be most common for the application to query the data by.
- E.g. Index instagram posts by user_id so that you can query posts made by one user.
Scaling and Sharding
- When data gets to large for 1 DB node, you need to store the data across multiple DB nodes.
- To choose the shard that the entry should live on, you should use one column as the shard/partition key
- You want to shard by the primary accessing key so that most queries will stay within one shard.
- Avoid cross-shard queries by keeping all related content on the same shard
Managing Multistep Processes
The Problem
- Sometimes, in order to process a user’s request, it takes coodinating between many different services
- Example: Buying an item from E-Commerce Platform
- Processing the payment
- Reserve inventory
- Creating shipping label
- Each step in this process has the chance of failing, and system needs to be able to handle that
Solutions
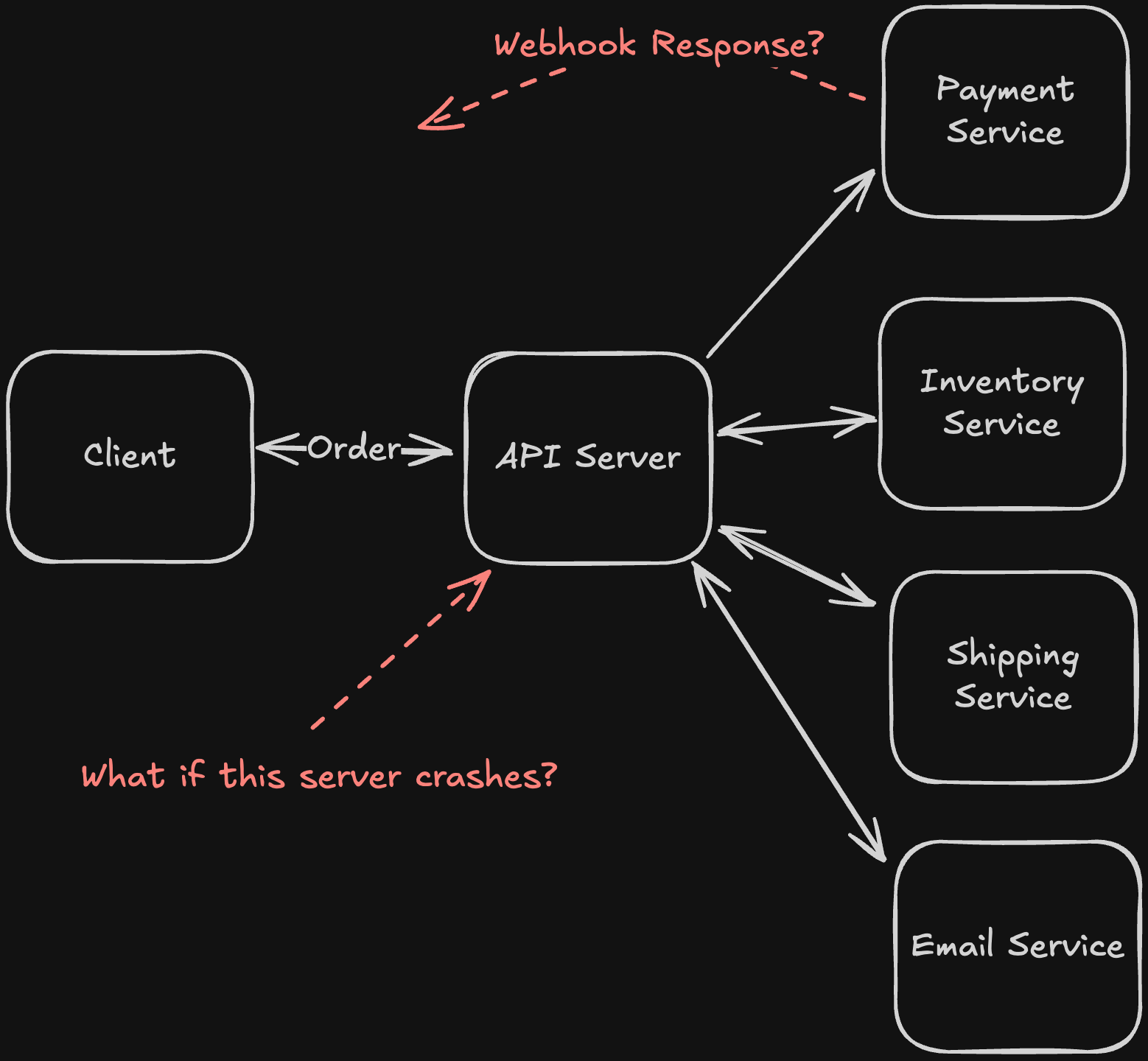
- Single Server Orchestration
- You have one server that is performing the orchestration of everything, calling each necessary service independently
- This is good if you do not have any complex state management or failure handling
- Not good if you need to manage state, as you would be screwed if the server goes down for some reason, as managing state becomes too complex.
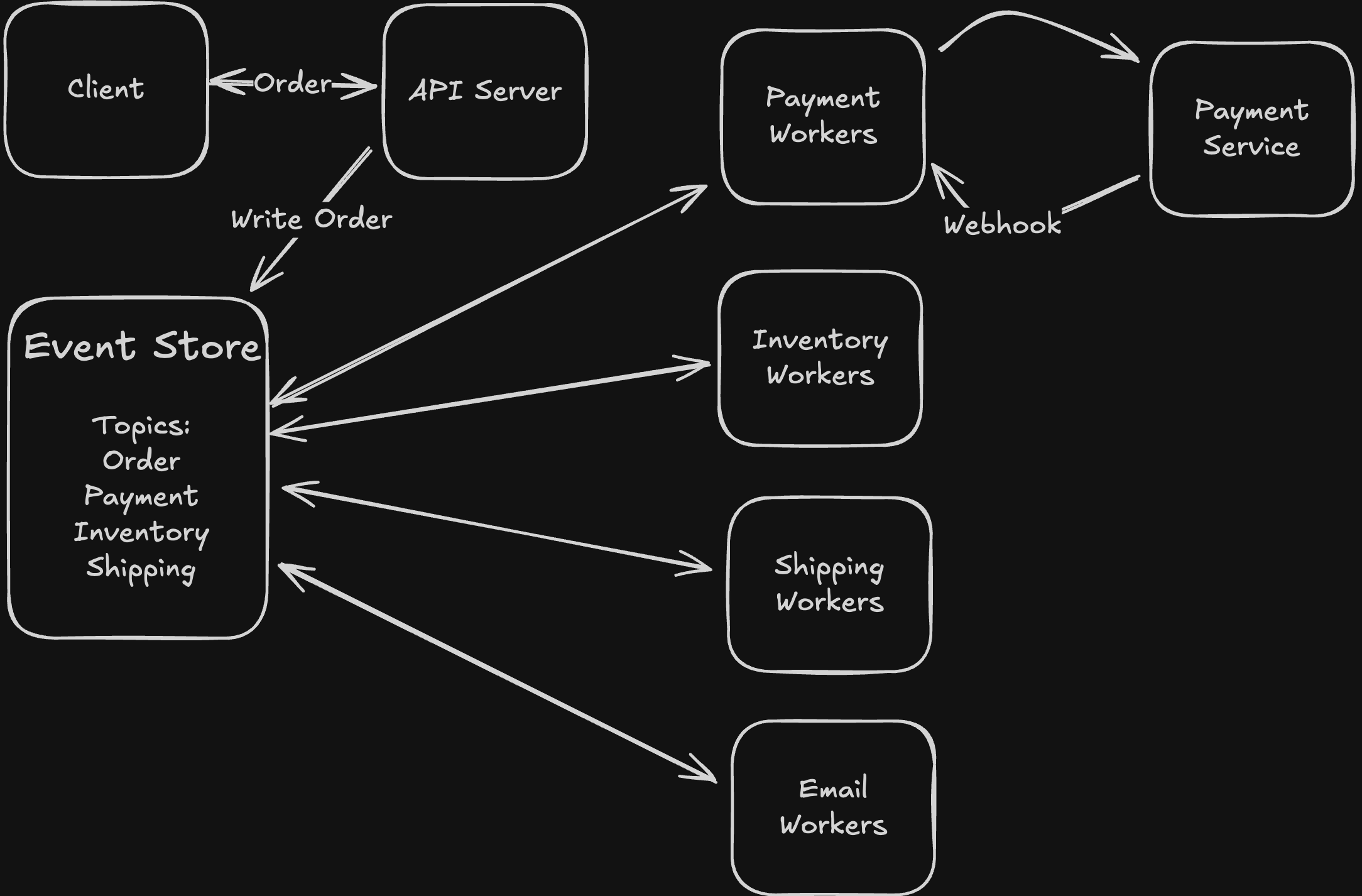
- Event Sourcing
- The most fundamental solution to the problem
- You append all events that happen to a durable log that represents what has happened, and this can be used to derive ths state of a process.
- You store all of these logs in the event store, and also use the event store to orchestrate the steps, initiating the next one when it is time.
- Whenever an event takes place, it gets written to the log, and there will be some worker node that is listening for this exact event, and when it sees it, it will be initiated to perform its job
- Example
- A payment worker sees an “OrderPlaced” message in the log, and initiates payment service to charge payment instrument
- Payment service writes “PaymentCharged” to log, and Inventory service sees this message and looks to reserve one of the items.
- It is like event driven architecture, but with API calls instead of Pub/Sub
- Provide the following advantages:
- Durable
- Fault tolerant
- Scalable
- Observable: Engineer can see the logs being published to it.
- It can be a lot of infrastructure overhead, as you will need a separate cluster to work as the event store
- Workflows
- Multi-step process, at its core, is a workflow that we are trying to define, which is a long running process that can handle failures and continue where they left off.
- There are two ways to do this, either with Worflow Systems or Durable Execution Engines
- They provide the benefits of event sourcing without the infrastructure overhead.
- Durable Execution Engine
- Writing long-running code that can move between machines and survive system failures and restarts
- You write a function that describes the workflow, and engine handles its orchestration
- It gets run in special workflow environment that produces deterministic results no matter what to be able to recover from failues.
- Workflows
- Define the high level flow of system
- Enables replay-based recovery (e.g. if an activity fails, it redoes the activity, and will reproduce the same results)
- Activities
- The individual steps of a workflow
- These need to be idempotent, so that when a workflow has to redo an activity for recovery purposes, it doesn’t have side effects
- Examples of this is Temporal, which is a popular durable execution engine.
- Managed Workflow Systems
- More declarative approach to define a workflow
- Think Apache Airflow or AWS Step Functions
When to use in Interviews
- Not a popular thing in most interviews.
- Only use as needed
Common Interview Scenarios
- State machine or stateful processes
- Payment System
- Or systems engaging with payment systems (e.g. Uber, Amazon)
- Human in the loop scenarios
- E.g. Uber, with driver having to accept or decline a ride.
When not to use
- Most CRUD operations will not need it
- High frequency, low number of operation jobs
- Simple asynchronous processing: use message queue.
Common Deep Dives
How to Handle Updates to Workflows
- If you are adding or deleting a step, how do you make sure current workflow executions will be executed successfully.
- Workflow versioning
- You keep old version and new version deployed at same time. All existing workflows will use old version, all incoming workflows will use new version
- Workflow Migrations
- In declarative workflows, when you add the step, all workflows will take the new path
How to keep Workflow State Size in Check
- Only keep the information you really need in state.
- If it can be offloaded to a DB, that is an option
How to ensure Step runs exactly once
- Make sure the operation is idempotent
Handling Large BLOBs
The Problem
- How to handle trasnferring large Binary Large Object (BLOB) over the network
- Application server can only handle a limited size for data transer.
- You need a way to circumvent the application server and directly request to the Object Storage (e.g. S3)
The Solution
- You give client temporary scoped credentials that allow client to interact with the object storage, and the application server just used for authentication purposes.
- You can do this with Presigned URLs
- Simple Direct Upload
- App server receives request from client to upload object to storage.
- User is validated, and a temporary presigned URl is generated by server that encodes permissions for the client to upload file to location
- Server uses cloud provider credentials to generate URL, and it can limit the size and type of file that client can upload
- Simple Direct Download
- Works basically the same way as the upload.
- Also can use Content Distribution Networks (CDN) to act as geographical cache to be able to increase speed of download.
- Resumable Uploads
- How do you handle the situation where you are 99% complete on a download, but it fails due to some server or network error.
- You can upload chunks of the file at a time with range headers on them, and if there is a failure, the client can receive the range header that was last completed to allow the client to resume the upload from last succeeded chunk
- Once all chunks are uploaded, Object storage receives a completion signal and assembles the full objects.
- State Synchronization Challenges
- A common pattern is to store object metadata in DB, but it becomes hard to keep S3 and DB in sync with this data (e.g. the status of the upload.)
- Race Condition: DB shows that the status is complete because all chunks uploaded, but S3 has not assembled the object completely.
- Orphaned Files: Client uploads s3 object but crashes before it can update the DB, so file does not exist in DB.
- Network Failures: Completion notification from S3 never reaches the servers.
- These are fixed by first having the s3 emit the notification, so it is the source of truth, and there is a periodic reconciliator that catches straggled files
- A common pattern is to store object metadata in DB, but it becomes hard to keep S3 and DB in sync with this data (e.g. the status of the upload.)
When to use in Interviews
- Common Scenarios
- Youtube
- Upload videos to Youtube.
- Download and/or stream videos using Cloudfront sending video segments
- Instagram/Photo sharing
- Upload images directly to S3, emit notification to perform some processing
- Chat Apps
- Sending images and videos through chat. Upload to s3, and pass around a reference to the same file.
- Youtube
- When not to use
- If you have small json files that are < 10 MB
- If you have synchronous validations that need to be done on the file contents, this will not work because it has to go to server
- If you need immediate response in UX, not good to use
Common Deep Dives
How to handle “fail at 99%” situation
- Use the chunked data upload
- Client can query qhich chunks have been uploaded, and start from first failed chunk
- Cloud storage keeps track of uploads with sessions, and keeps track of state to let client know what chunks have completed.
How to prevent abuse
- Do not allow users to immediately access the files they upload
- Needs to go through quarantine and santization process before going to public bucket
How to Handle Metadata
- Use a consistent storage key that includes useful information but prevents collisions.
How to have fast downloads
- Use CDNs, so that first user to access object retrieves from object storage, after this, the content will be sent to CDN, which are distributed globally geographically so that subsequent requests for the same object is faster
- CDN doesn’t help with large file uploads, as it doesn’t handle the “fail at 99%” type failures
- To fix this, you use range requests, which basically means adding the specified range of bytes you want of a file in the HTTP request.
- This enables resumable downloads
Managing Long Running Jobs
The Problem
- You want to expose an API that allows users to perform some long running job (e.g. generating a PDF), but the process takes a long time (> 45 seconds)
- This will cause the request for this to timeout if performed in a synchronous manner
- How can we allow users to initiate these jobs without timing out issue.
The Solution
- Split the process into two different phases
- Phase 1 is once the request is made, push the request to some request queue that feeds into the processing job/service. Server just validates and queues request
- Actually executing the job. The processing service consumes from the request queue and performs the job.
- This decouples the submission of a request from the processing of a request
- Advantages
- User gets a faster response, leading to seemingly better user experience
- Independent scaling - you can scale webserver and worker service independently without affecting each other.
- fault isolation
- Disadvantages
- Increase complexity and operational overhead in the service
- Need to keep track of the jobs’ statuses.
- You have to live with eventual consistency.
How to Implement
- There are 2 tools that you need
- Message queue
- Pool of workers consuming from the queue
- Message Queues
- Can use RabbitMQ, SQS, Redis + BullMQ, Kafka
- Workers
- These are normal servers that are running the processing service (e.g. EC2/ECS, Lambda)
- Putting it together
- Web server validates a request. Create a status of pending for job
- Server creates job id and pushes the message to queue
- Job ID is returned to client as response
- Worker pulls from the message queue, and sets the job status as processing
- Worker does processing
- Worker finishes, and the results are stored somewhere (e.g. DB)
- Job Status updated to completed or failed, depending on outcome
When To Use
- Common Signals
- There is mention of slow operations (e.g. video transcoding, image processing, data exports)
- The math does not work out
- When doing back of the envelope calculations, you see that service cannot scale as high as you need for the constraints with synchronous processing
- You have different operations in the request that would be better served on different hardware
- e.g. ML workloads better on GPUs.
- Examples
- Youtube
- Video upload triggers video transcoding, generating thumbnail, and generation of closed captions
- Instagram
- When photo or video uploaded, image recognition performed and image filtering performed
- Uber
- Ride matching is asynchronous, and so is location updating to not overload server
- Payment Processing
- Actually processing a charge of a payment instrument takes a long time because of verification and fraud detection
- Dropbox uploading files
- Scanning for viruses, indexing files for better search, and sync files across multiple devices
- Youtube
Common Deep Dives
How do you handle failures
- How can you detect when a worker crashes when processing a job?
- Usually, implement a heartbeat mechanism between queue and workers that lets the queue know that the worker node is alive
- If worker does not check in with queue, queue will assume it is dead and retry the job on a different node
- Need to choose a good interval for heartbeat such that it is not constantly polling the worker but also quick enough that we aren’t unnecessarily waiting.
Handling Repeat Failures
- If a job keeps failing, most likely it is not a host issue, but it goes down an error path in the code, so there is a bug.
- After a certain amount of retries the event, then message should go to DLQ, and engineer should be alerted of the new DLQ message
Handling Repeat Events
- You may receive duplicate events because client becomes impatient and clicks “Submit” button multiple times
- Should use idempotency keys for events so that events are idempotent and repeat processing doesn’t cause side effects.
Managing Queue Backpressure
- What to do when you have too many messages coming into the queue
- You can slow down the acceptance of jobs by throttling the API itself by rejecting messages being sent to queue if queue has too many messages
- Can also implement autoscaling so you spin up new workers when too many messages
Handling Mixed Workloads
- You have a mix of long and short jobs, but long jobs will delay short ones from being processed
- You can create multiple queues, each one specialize in different type of jobs, and the job can be routed to the specialty queue it needs to go to.
- Makes sure that long jobs go to long job queue, and short jobs go to short job queue.
Orchestrating Job Dependencies
- You can use orchestration tools such as AWS Step Functions
- For simple chains, you can populate the queue message of the next job with context of the previous queue/worker it came from.
Example Questions
Design FB News Feed
- For social media product design, consider adding follow relationships as actual entities with their own tables.
- Pagination: add pagination to API using the following
?pageNumber={pageNumber}&pageSize={pageSize}
The above will add page based pagination
?cursor={cursorPointer}&pageSize={pageSize}
The above will add cursor based pagination. Cursor based pagination is better if you want infinitely scrolling pages, and records can update frequently, so you don’t want page drifts/
-
For DynamoDB, make sure to specify the sort key and the partition key per table.
- Instead of just “indexing” a certain field, you need to create Global Secondary Indexes to be able to speed up requests by a different field. The GSI must have a partition and a sort key as well.
-
Fan-out Reads: This happens when a single request can fan out into a large amount of reads of a database. This can cause a latency problem as these many reads can take a long time while the user is waiting for the request to be fulfilled.
- Don’t want > 1000 reads from one request.
- In this case, for feed generation, we can have the feeds be generated when posts are made (at write time)
- Posts are created, and posts get sent to a queue that is consumed by Feed generation workers. The workers will asynchronously add the posts to the feeds of all the users that the post needs to go to.
Your instinct here should be to think about ways that we can compute the feed results on write or post creation rather than at the time we want to read their feed. -
Fan-out writes: Only problem is, when a user has a large number of followers (e.g > 1 milltion) one write of posts can lead to a fan out when adding the posts to all the feeds, as the post will need to go to > 1 milltion feeds, so we run into a fan-out write problem
- To fix this, we avoid the precomputing feed step for posts from users with large number of followers. Instead, they will be retrieved at feed retrieval time using normal read techniques.
Design News Feed Aggregator
- RSS Feeds: A simple XML format used by news aggregators allows publishers to forward their content to news aggregators like Google News. It works over HTTP, so we just use GET requests on feed URLs from publishers to get the content.
- Web Hooks
- This is a good solution if you want instant updates from a data/information source instead of having to wait some time due to polling.
- We provide a webhook endpoint that publishers can post to when they have new stories, and this will automatically trigger the published story to be sent to the Articles DB for us to facilitate in news feeds.
Design Tinder
- When there are swipes left and right on profiles, we will likely have a more abnormal read/write pattern. We will have a lot more writes for swipes.
- For detecting matches, we will need to prioritize consistency over availability, as there is a chance that the match is completely missed with eventual consistency.
- For notification delivery to devices
- Need to track devices for users in the DB to know which devices to send notifications to.
- To send notifications, use Apple Push Notifications (APN) and Firebase Message Protocol (FMP) as the service to send notifications to devices.
- If using Cassandra, and still want to have a sense of strong consistency (e.g. when you want quick but conssitent retrieval of matches)
- Use a redis cache instance to store all “Yes” swipes. Redis is single threaded and allows atomic operations so you can enforce consistency, but is also in memory, so quick. You want to store user1:user2 relationship if there is a “yes” swipe. Then you search for user2:user1 key. Redis entries are periodically flushed to DB.
- To ensure fast retrieval of profiles, use a precomputed feed model.
Design Strava
- Offline Usage
- Use an in memory buffer that stores activity statistics and data for the current activity that can later be sent to remote DB.
- Periodically flush this buffer to on device persistent storage (e.g. sqlite) in the case of device crasing.
- Sync the local DB to the remote DB after the device goes back online.
- Getting activities for user vs friends
- Introduce parameter (FRIEND|USER) to GET /activities API to signal getting activity for user or activity for friends
- Get live updates of current activity
- All data for current activity is found locally on device (e.g. GPS information, clock, etc.). Because of this, you don’t need to make server calls to get updates of activity. Just use local device data. Periodically, send these updates to remote DB.
- Leaderboard generation
- To efficiently generate leaderboard, you should use a Redis cache instance and use Redis Sorted Set data structure. Key value pair of user, totalDistance stored, and this is updated every time an activity is updated.
- Using sorted set leads to efficient retrieval
Design FB Live Comments
- Pagination/Infinite Scrolling
- When watching live stream, user should be able to scroll up and look at past comments before they joined the stream (i.e. infinite scrolling of comments)
- To get past comments, we use pagination, more specifically cursor pagination. Cursor must be a unique value per item that points to a specific item in a set of results.
- We can use
createdAt+commentIdcomposite cursor key so that we will preserve order, and we can avoid collisions by adding comment id to the end.
- Server Side Events
- Users need to see new comments in near real time, so that when a comment is posted to a livestream, the comment will appear on other users’ devices immediately
- We do this by establishing a server-sent event (SSE) connection from server to client. This is to establish a persistent connection that the server can use to send comments to the client. We do not use Web Sockets because there is nothing that the client needs to send the server in this case.
- How to handle the large scale (> 1 million videos, > 1k comments per second)
- The common pattern is to perform horizontal scaling, but in this specific problem, it is a bit harder because of the following scenario:
- If user1 is on server1, and user2 is on server2, each user has a SSE connection to their own server. If user1 posts a comment, how would server2 know that that comment was posted?
- We can use consistent hashing + partitioning to solve this problem
- First, we will have the comments published to a PubSub (e.g. Kafka) that will be partitioned by the live video stream id.
- The horizontally scaled SSE servers will be subscribed to these Kafka PubSubs, but they will only be subscribed to the necessary topics they need to handle via the same consistent hashing that is used for the publishing to Kafka topics.
- We can then use an L7 load balancer that will route SSE connections from users to the appropriate SSE server based on the stream id of the livestream they are watching.
- In this way, The full end to end experience of the user will have a deterministic server + topic that will handle its connection, so that all comments of one video stream will be sent to all the users that need to see them.
- The common pattern is to perform horizontal scaling, but in this specific problem, it is a bit harder because of the following scenario: